Providing staged corpus access at multiple levels
To maximize corpus usability and minimize costs
16th Edition of the International Conference on Linguistic Resources and Tools for Natural Language Processing – Iași and online, 2021-12-13
Overview
1. The Challenge
Special Situation in Linguistics
Our most important primary research data is not easily accessible
-
corpora often cannot be copied, because of
-
IPR and license restrictions
-
their size
-
-
interpreting corpus data can be pretty complex
-
how to analyze corpora depends on the research question and is itself subject of ongoing research
-
»curse of dimensionality« (Bellman 1953)
-
LNRE distributions with linguistically interesting phenomena somewhere in the long tail
-
having properties of s social artefact, language is a moving target
-
-
it's not possible to implement all desired methods in a corpus analysis platform
-
Special legal problem
-
Linguistic research data is usually affected by third parties' rights
-
authors and publishers
-
not part of the scientific community
-
-
affected rights:
-
intellectual property rights
-
database rights
-
general personality rights
-
-
open-data-models from other disciplines are not transferable to linguistics
-
this will not change fundamentally
This will not change fundamentally
Ultimately: collision of fundamental rights
➞ Open-Data-Models not applicable
-
models from other disciplines:
-
I make my corpus available to you and in turn, you make your corpus available to me
-
we make all our corpora available since the taxpayers financed them
-
-
lead to nothing:
-
my corpora = your corpora = our corpora = our corpora, which the taxpayer paid = {}
-
...
-
You cannot transfer rights you don´t have
(Slide by our copyright expert Paweł Kamocki showing Victor Lustig)
You cannot transfer rights you don´t have
(Victor Lustig was an impostor who sold the Eiffel Tower to scrap metal dealers)
Big corpus data is not easily accessible

And Corpus data cannot move
for legal reasons

Topic of this talk
-
report on approaches to make corpus data as actually usable as possible
-
despite the aforementioned challenges
-
at feasible costs
-
-
used at the Leibniz Institute for the German Language (IDS),
in the context of-
German Reference Corpus DeReKo
-
corpus analysis platform KorAP
-
2. Background: DeReKo and KorAP
German Reference Corpus DeReKo
IDS corpora of contemporary written German (Kupietz et al. 2010, 2018)
-
construction started in 1964
-
aims to serve as an empirical basis for German linguistics
-
has ~ 40,000 registered users
-
samples the current use of written German
-
since ~1956
-
is continually expanded
-
DeReKo now contains more than 50 billion tokens
For the most part consisting of newspapers
Many thanks to all license donors!

With a good regional coverage
of German speaking areas
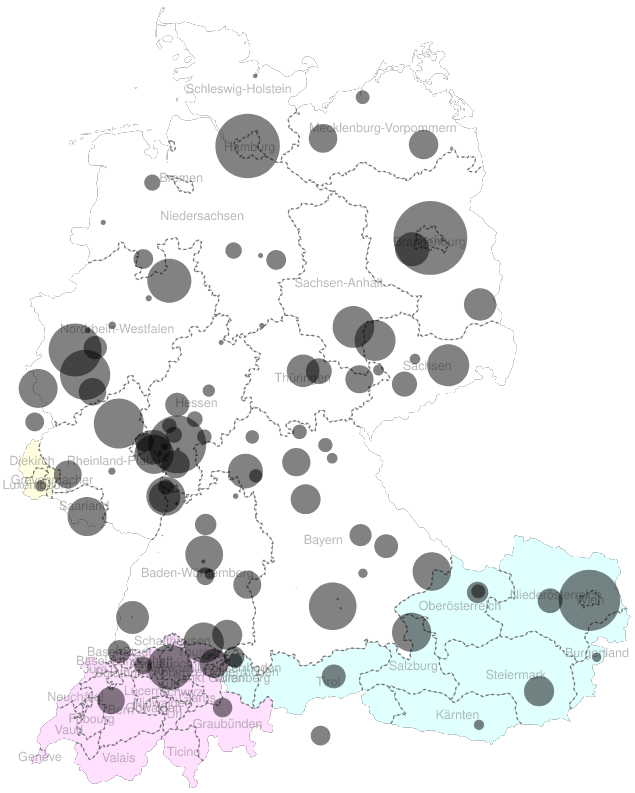
but also Many popular and trade magazines

And a big range of many other text types
like e.g. children's and youth literature

DeReKo is accessible via COSMAS II
https://cosmas2.ids-mannheim.de/ (Bodmer 1996)
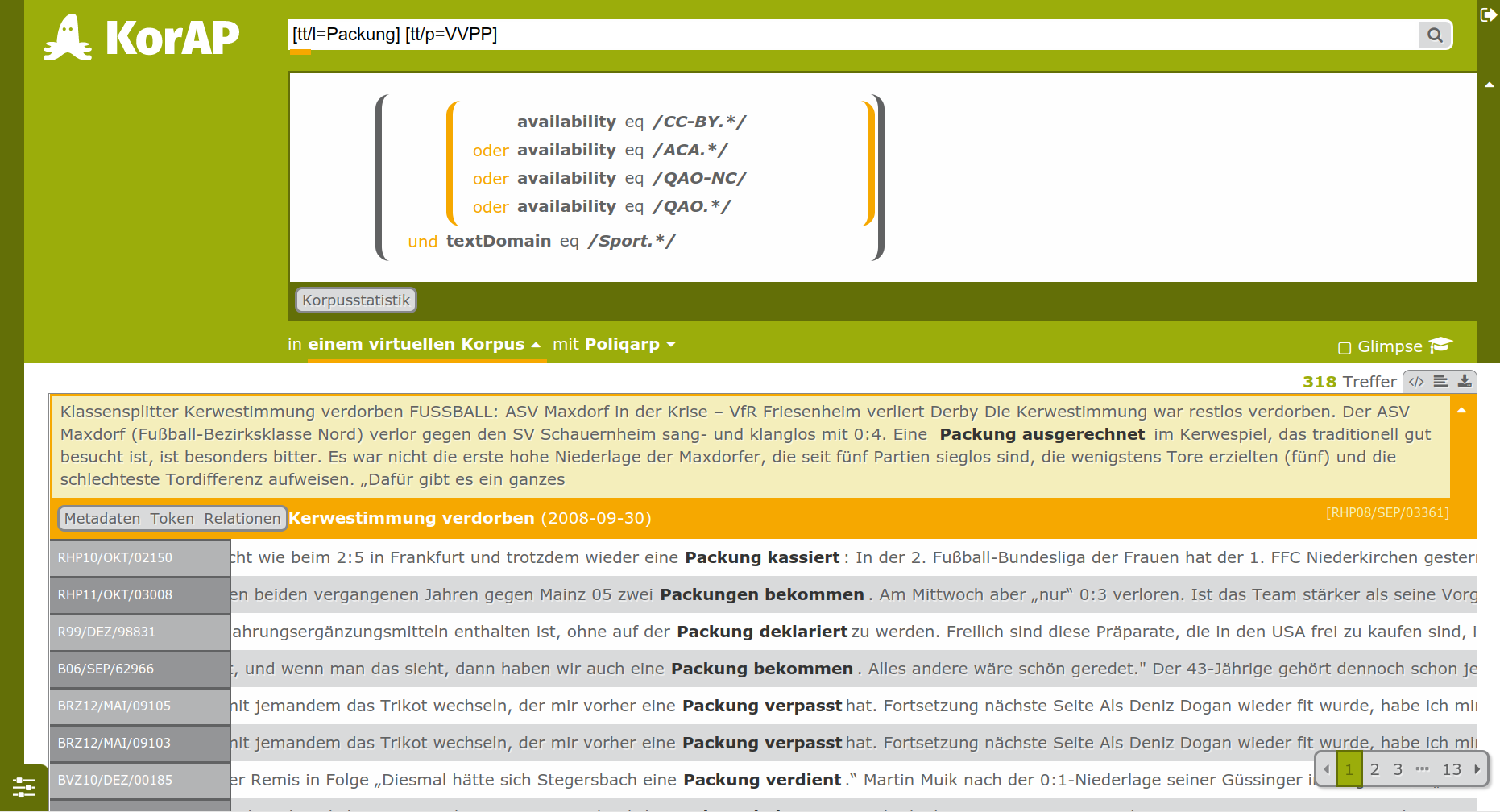
And the new analysis platform KorAP
https://korap.ids-mannheim.de/ (Bański et al. 2012)
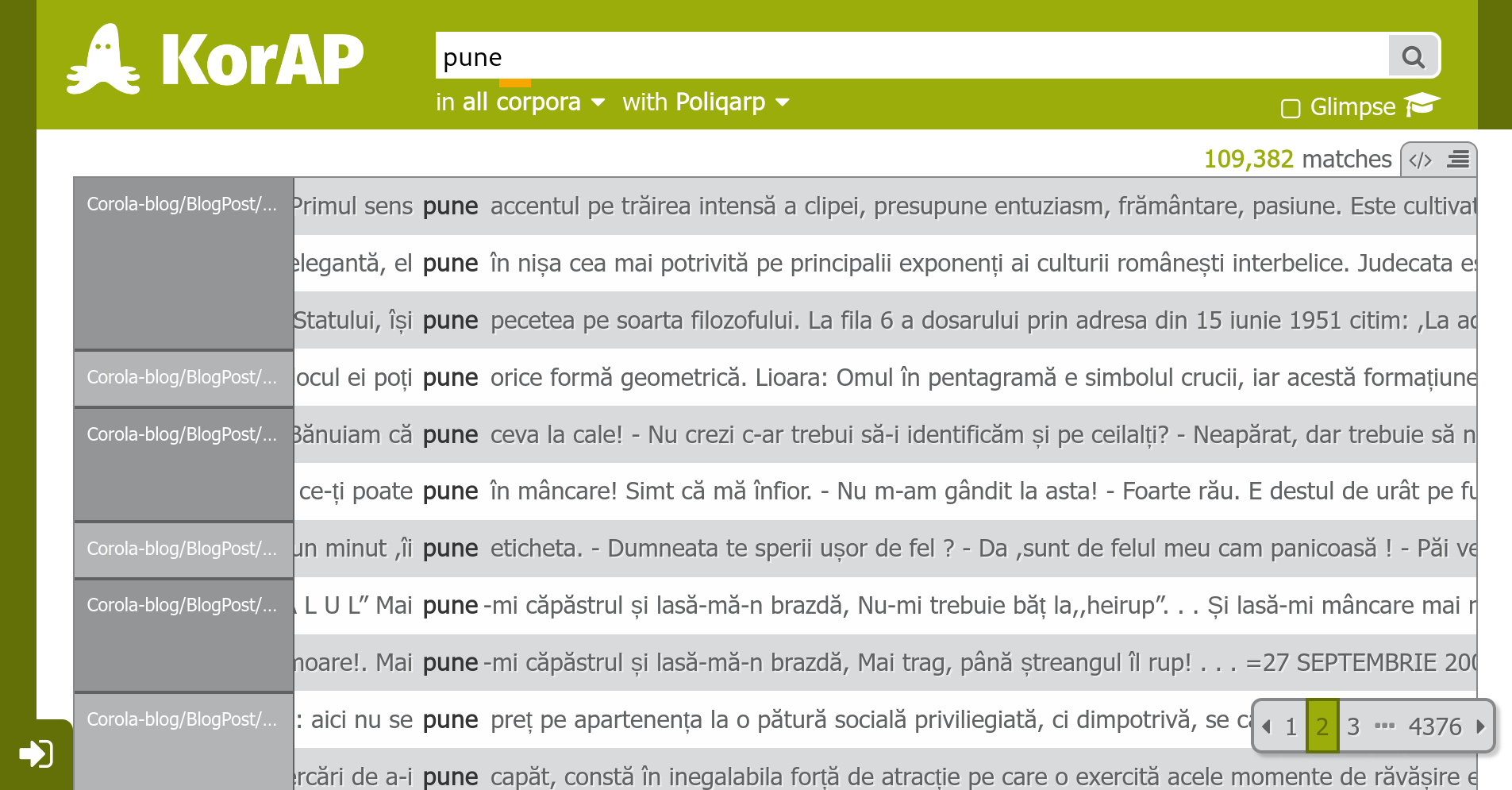
Also available for querying CoRoLa
at https://korap.racai.ro/ (Cristea et al. 2019)
And for the Hungarian National Corpus HNC
https://korap.nlp.nytud.hu/ (Váradi 2002)
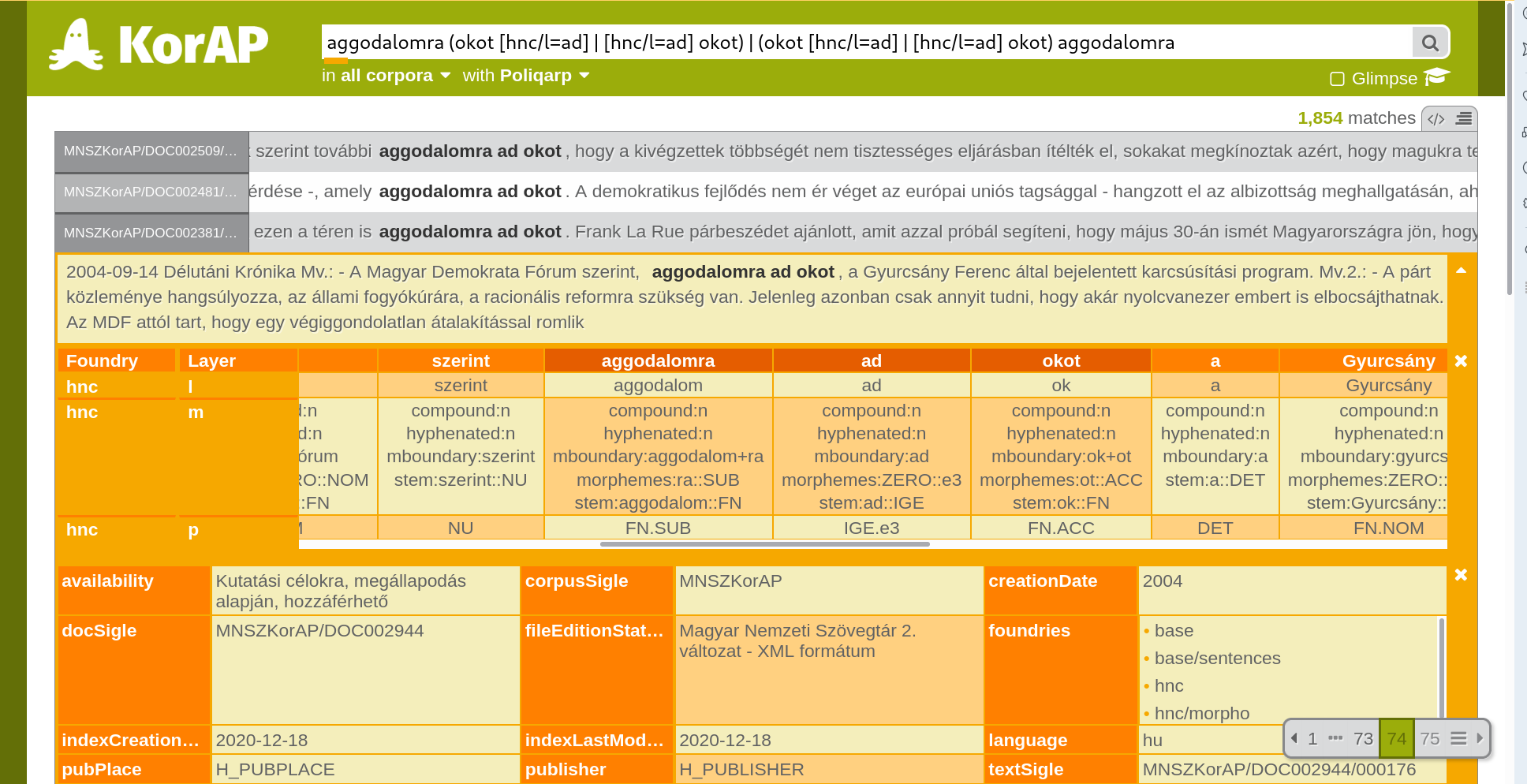
3. An initial (failed) attempt
Great opportunity in 2010
we successfully applied for funding for new corpus analysis platform 🎉
-
18,000 DeReKo users via COSMAS II platform
-
mostly German linguists
-
-
growing interests in more sophisticated applications
-
from more and more corpus linguistics experts
-
and from NLP / computational linguistics
-
that had completely switched to corpus based statistical approaches
-
-
-
CLARIN infrastructure was well established
Big Question
-
knowing that we will not be able to provide all ever desired functionalities,
-
can we use the funding somehow
-
to maximize the usability of the valuable corpus data?
-
also for sophisticated individual applications that we would hardly be able to implement and maintain ourselves?
-
for linguists
-
and ideally also for other users from other DH disciplines?
-
-
without interfering with our licences and the interests of right holders?
-
while keeping the follow-up costs manageable?
Initial Idea
inspired by grid computing
-
tackle the legal, scientific, and economical challenges
-
with an infrastructural approach
-
partially implemented in an OSS project
-
roughly following one of the basic principles of grid computing posutlated by Jim Gray (2004) ...
If the data cannot move
… pave ways to put the computation near the data!
To make the data accessible – legally and scientifically
Initial Idea: build a »Mobile Code Sandbox«
-
provide a virtual machine for user supplied code
-
with controlled output
-
-
but that turned out to be too cost-intensive and unmaintainable
-
like most other grid inspired approaches
-
in the lesser resourced DH disciplines
-
not only for us, but particularly for the users
-
-
new approach needed, much more focused on
-
feasibility, maintainability, economic efficiency
-
KISS principle
-
distribute work over several shoulders
-
4. Multiple access levels approach
Provide multiple Levels of Access
Kupietz et al. (forthcoming)
- 0
- User Interface
-
the web user interface
-
- 1
- Web Service API
-
accessible directly or via client libraries
-
- 2
- Plugin
-
user interface plugins
-
- 3
- Instance
-
independent access by fully customized installations
-
- 4
- Open Source
-
new features by source code contributions
-
- 5
- Corpus
-
direct access to corpus data (without KorAP)
-
Intended Properties of the levels
the higher the, the cheaper and the more application instances (Kupietz et al. forthcoming)
Level 0: User Interface
Not many consequences at this level
-
-
except that simplicity and Information on Demand principle (Diewald et al. 2019) can be followed quite far
Level 1: Web Service API
-
makes all backend functionality available
-
different query languages (Bingel & Diewald 2015)
-
complex expressions referring to multiple annotation layers
-
the definition of virtual corpora based on metadata properties
-
-
UI itself uses the API only
-
provides OAuth2 for authorized access to restricted data
-
offers unauthorised access to not copyrighted numerical data
-
accessible directly (➞ documentation)
-
and via client libraries for R and Python (Kupietz et al. 2020b)
API client libraries
Application areas
-
complex, multipart queries
-
applications where reproducibility and replicability is required (with varied query or corpus base)
-
providing features that are not yet supported by KorAP's backend or UI, currently e.g.
-
collocation analysis
-
aggregation of search results
-
-
aim: make programmatic use as easy as possible
-
in order to also pick up linguists who never coded before
-
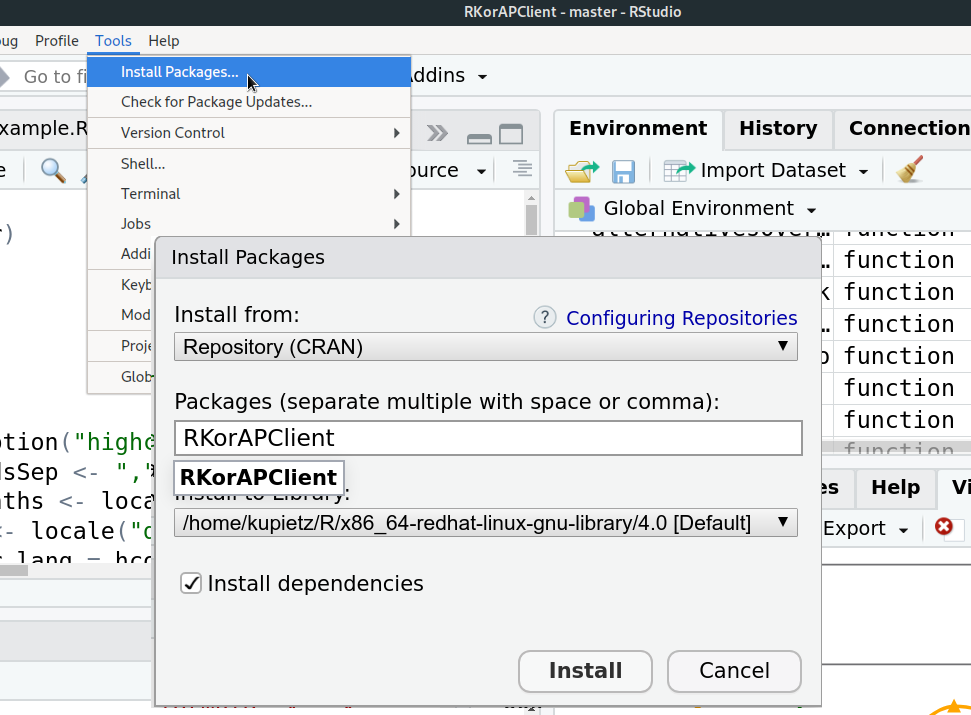
Installation of Korap’s R client Library is very easy
in RStudio: Tools ➞ Install Packages ➞ RKorAPClient
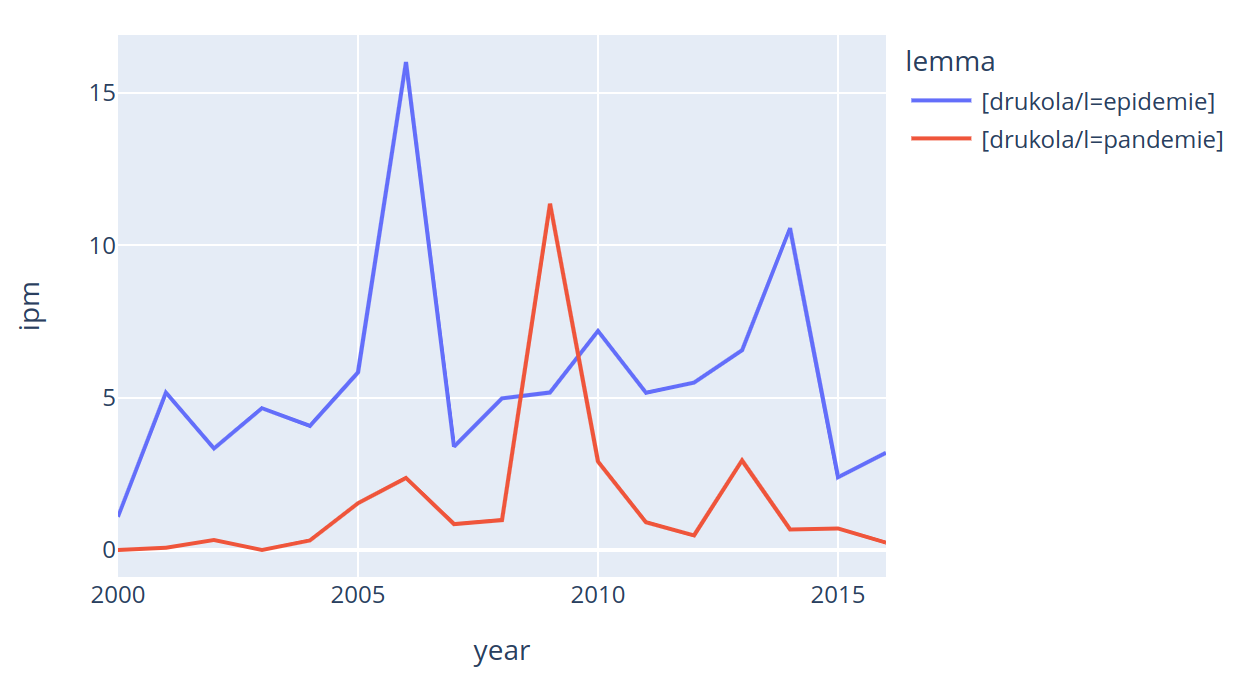
R-Script for a frequency plot
of the lemmas 'epidemie' and 'pandemie' in CoRoLa
library(RKorAPClient)
query = c("[drukola/l=epidemie]", "[drukola/l=pandemie]")
years = c(2000:2017)
new("KorAPConnection", KorAPUrl = "https://korap.racai.ro", verbose=T) %>%
frequencyQuery(query, vc = sprintf("pubDate in %d", years)) %>%
hc_freq_by_year_ci()
Frequency Plots
of the lemmas 'epidemie' and 'pandemie' in CoRoLa
Frequency plot with KorAPClient Python library
using pandas and plotly.express
#!/usr/bin/env python3
from KorAPClient import KorAPConnection, KorAPClient
import plotly.express as px
import pandas as pd
years = list(range(2000, 2017))
query = ["[drukola/l=epidemie]", "[drukola/l=pandemie]"]
df = pd.DataFrame({'year': years,
'vc': [f"pubDate in {y}" for y in years]}) \
.merge(pd.DataFrame(query, columns=["lemma"]), how='cross')
results = KorAPClient.ipm(
KorAPConnection(KorAPUrl="https://korap.racai.ro", verbose=True) \
.frequencyQuery(df['lemma'], df['vc']))
df = pd.concat([df, results.reset_index(drop=True)], axis=1)
px.line(df, x="year", y="ipm", color="lemma").show()
Frequency Plot with Python
using pandas and plotly.express
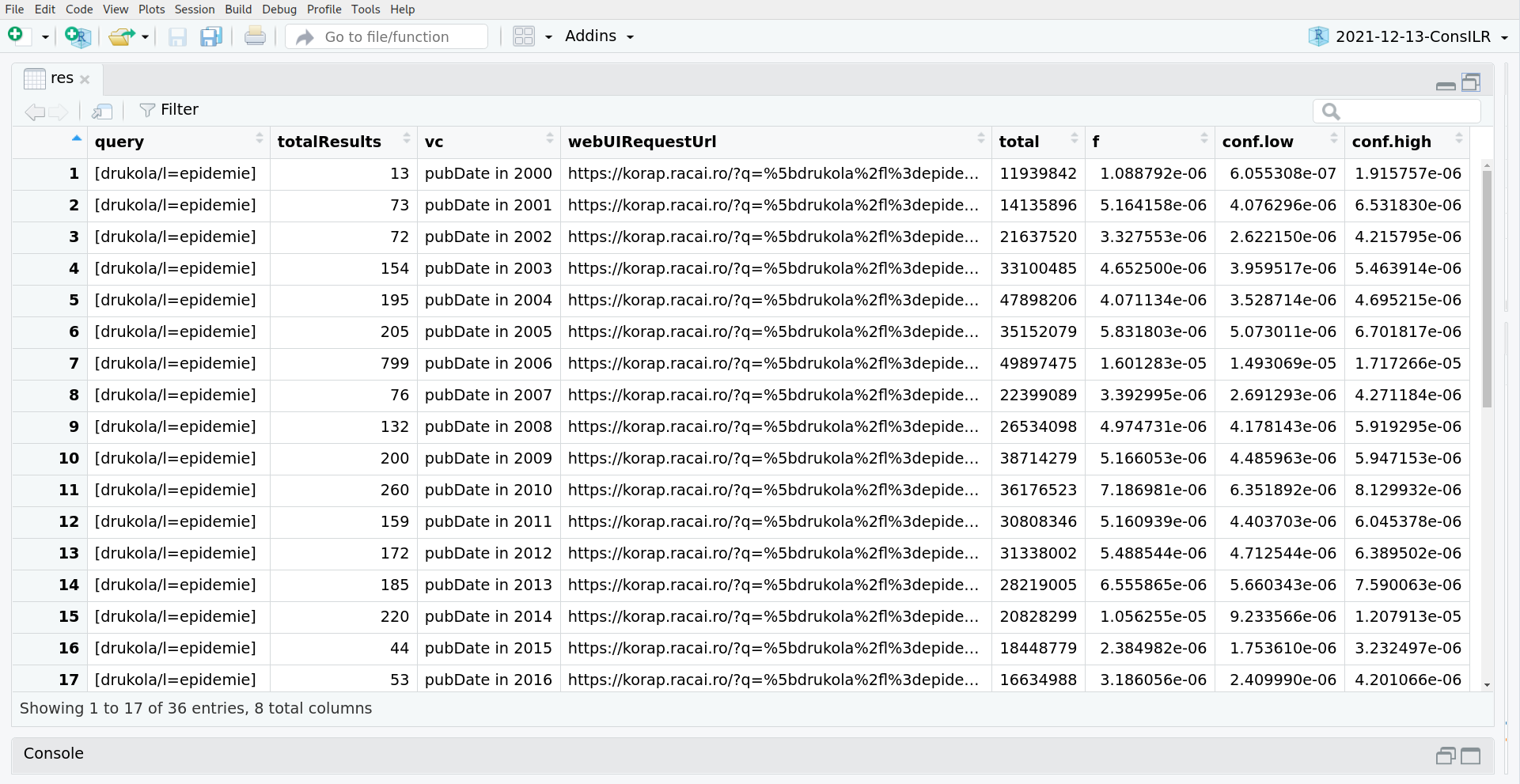
Data frame returned by the API
no login required for just numerical results
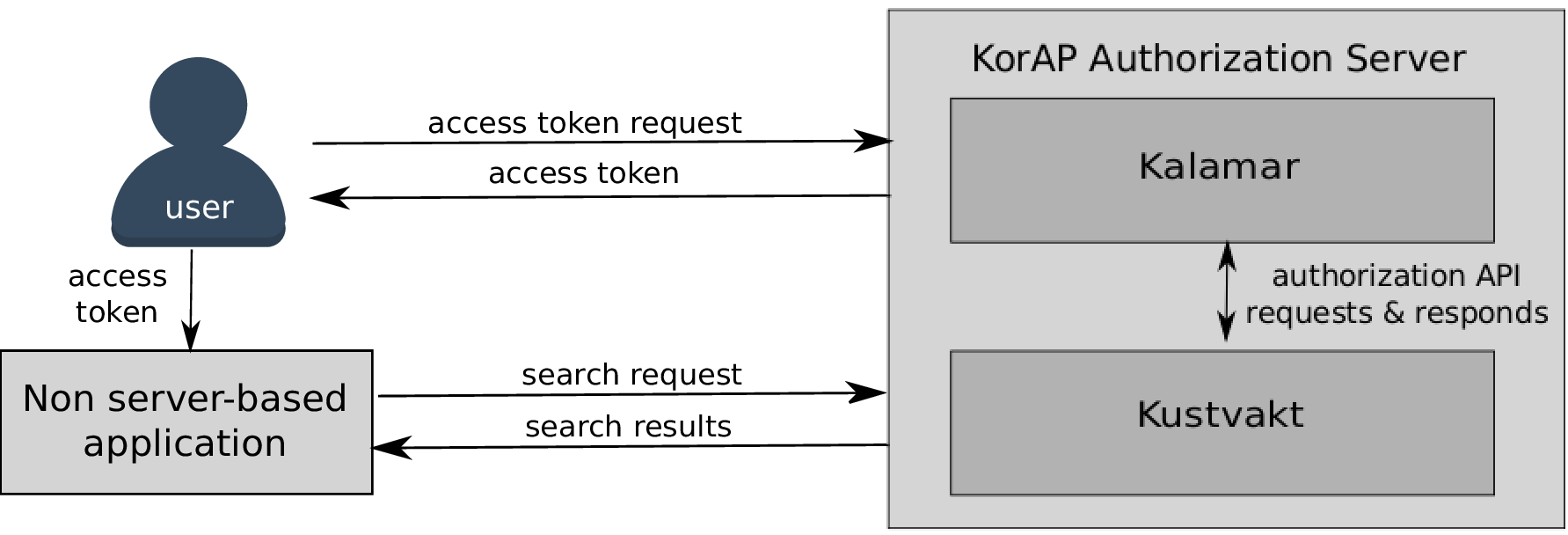
OAuth2 access grant flow for accessing copyrighted data
(Kupietz et al. forthcoming)
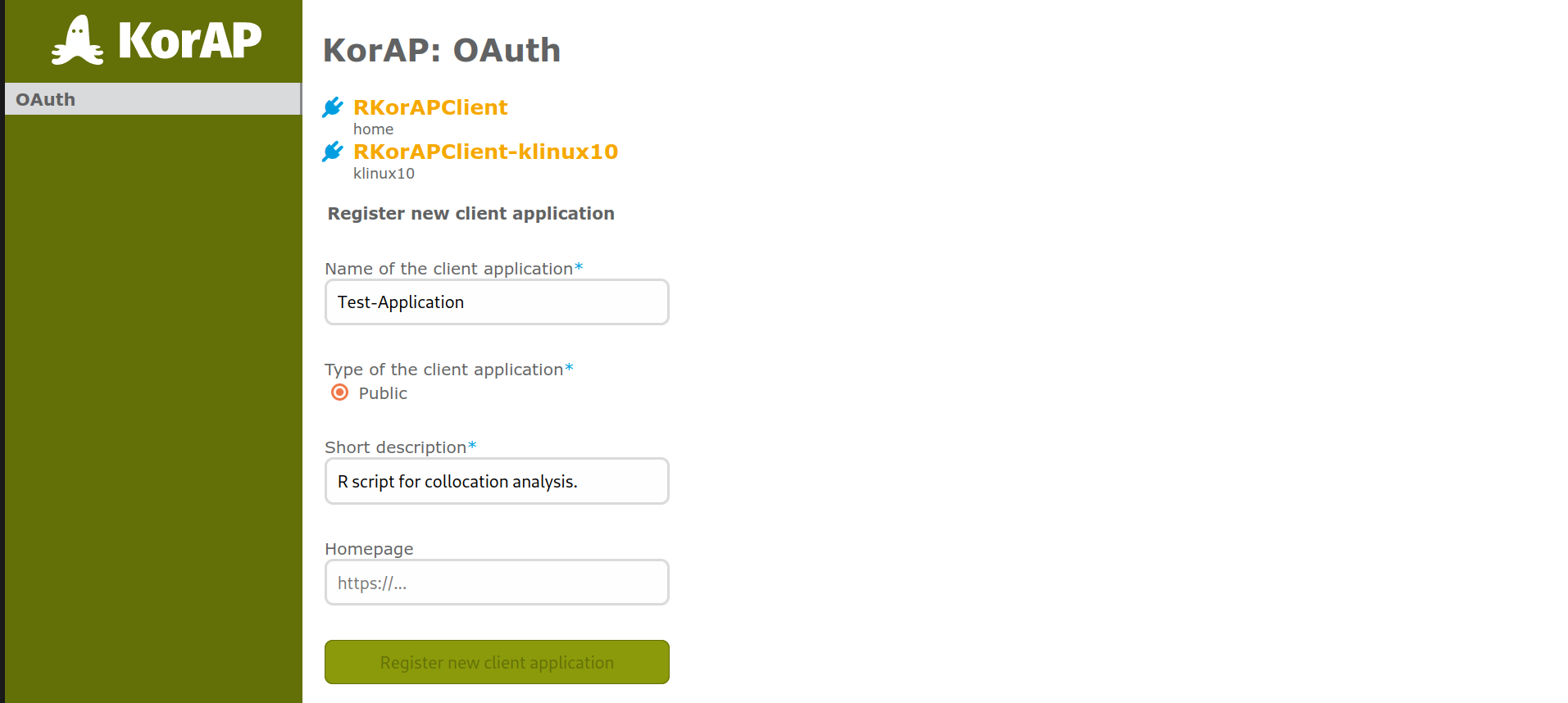
OAuth2 flow in KorAP: 1. Register an Application
… in KorAP's user settings
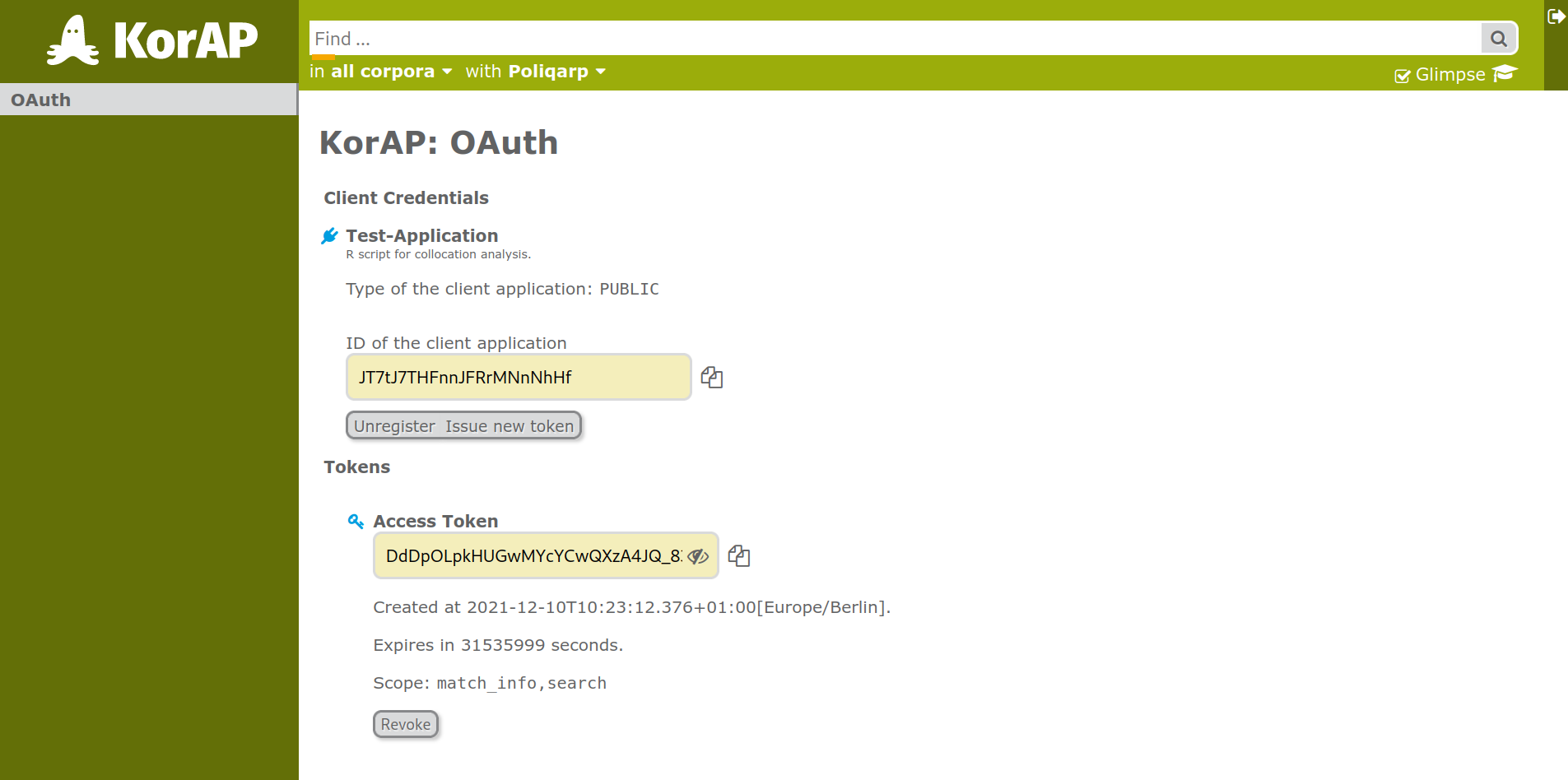
OAuth2 flow in KorAP: 2. Generate access token
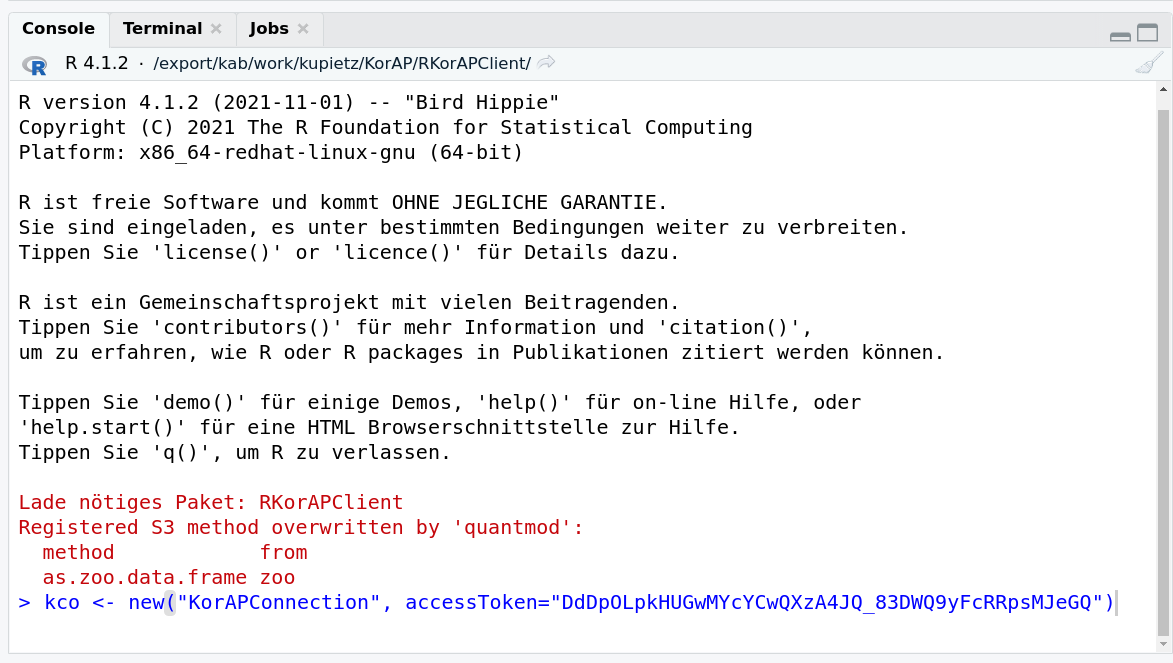
OAuth2 flow in KorAP: Use the access token
… in your application
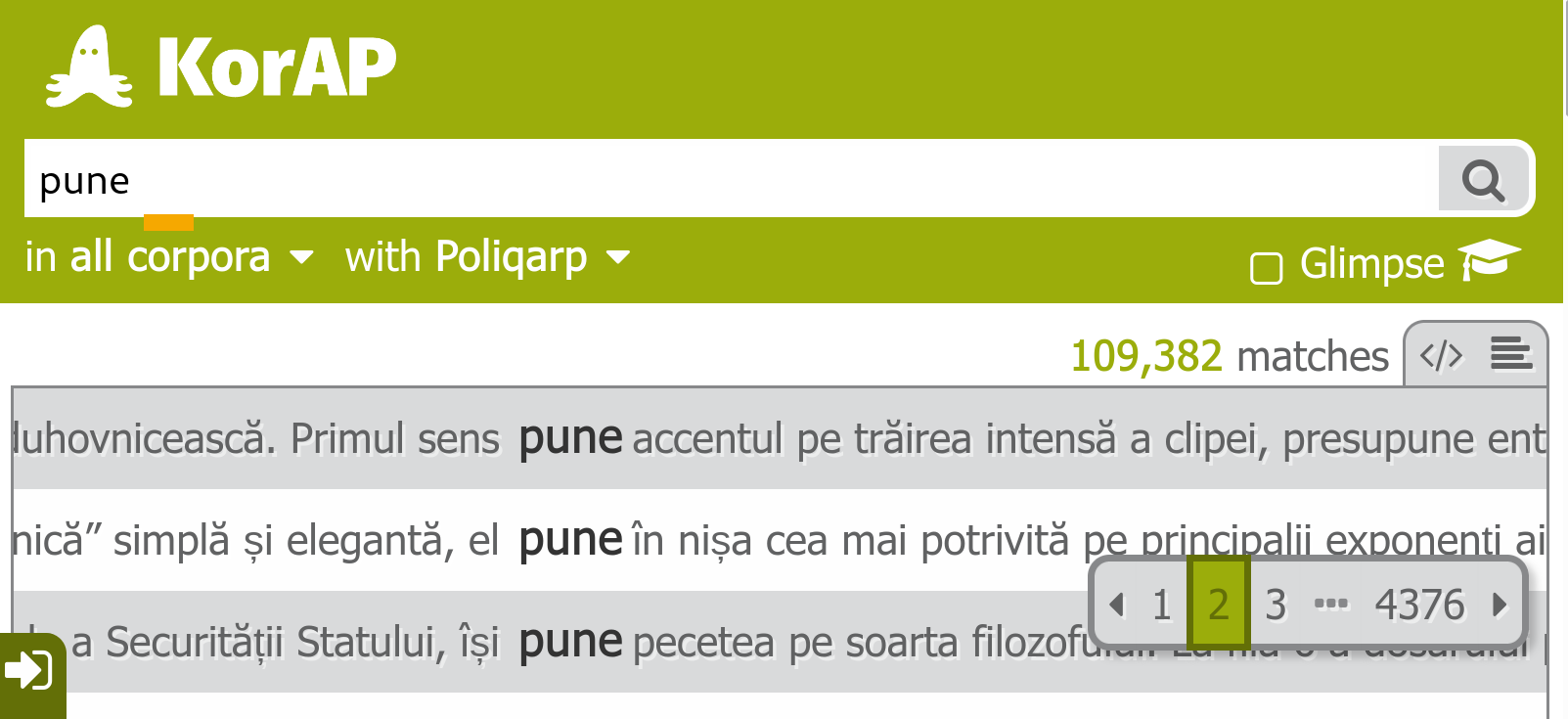
R-Script using collocation analysis
to identify light verb constructions with »pune în«
library(RKorAPClient)
df <-
new("KorAPConnection", KorAPUrl = "https://korap.racai.ro", verbose = T) %>%
collocationAnalysis(
"[drukola/l=pune] în",
leftContextSize = 0,
rightContextSize = 1
)
Output of collocation Analysis
to identify light verb constructions with »pune în«
Level 2: Plugins
Extension of different functional areas of the UI with widgets
-
search input
-
e.g. Lemma-Expansion
-
-
definition of virtual corpora
-
e.g. corpus visualization
-
-
search results
-
e.g. export
-
-
individual matches
-
e.g. annotation visualizations
-
-
...
Plugin Level - Architecture
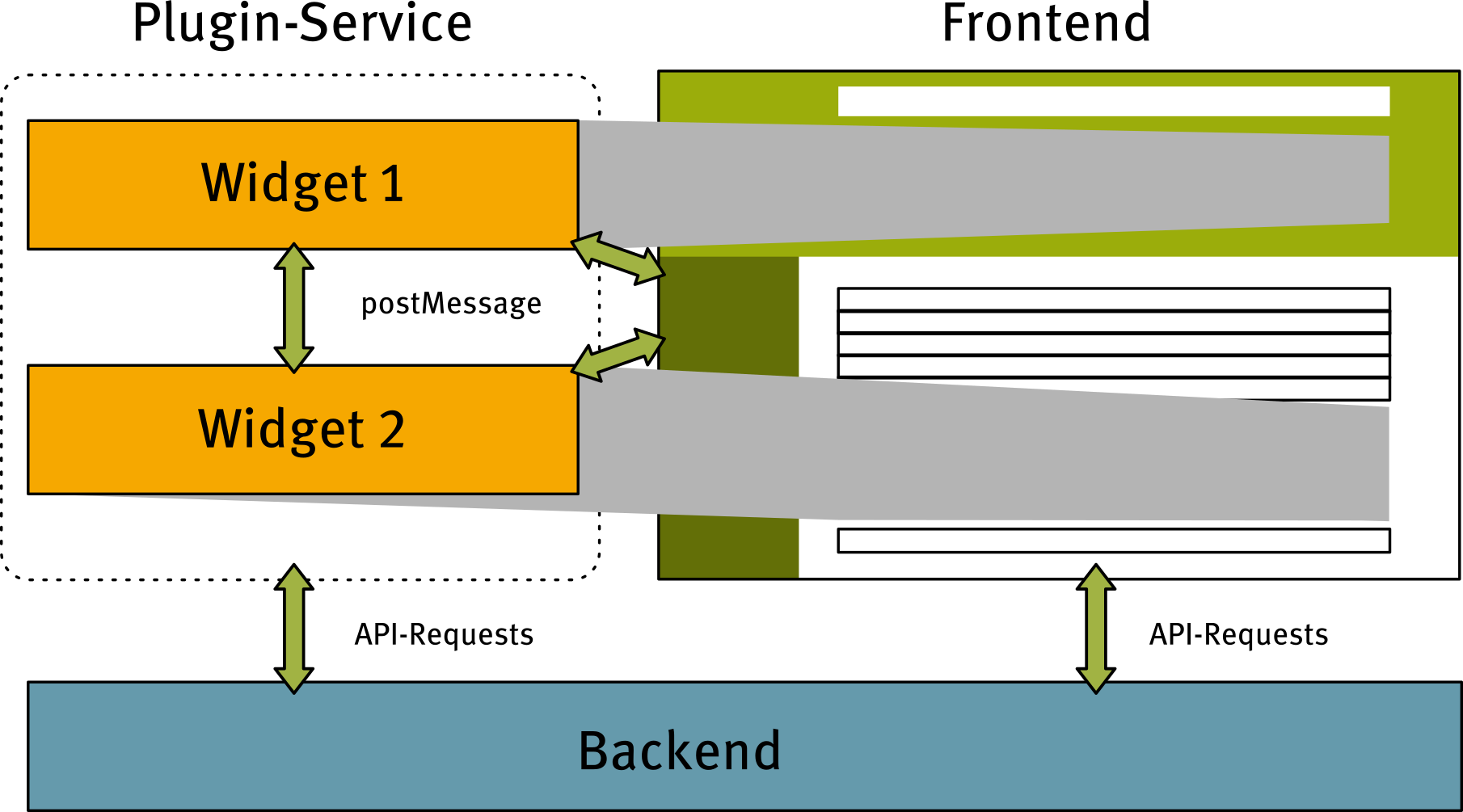
Application areas for the plugin level
UI extensions that …
-
… are only required by certain user groups
-
also in order not to overload the UI
-
following the IoD principle
-
-
… should be replaceable easily with variants according to specific needs
-
… are not intended to be maintained by the core KorAP team
-
in general:
-
much easier to more maintainable to add a plugin
-
than to develop a whole new UI based on the API
-
Current plugins
also serving as examples for external developments
-
not yet released:
-
query expansion with the inverse lemmatizer glemm
-
Export plugin
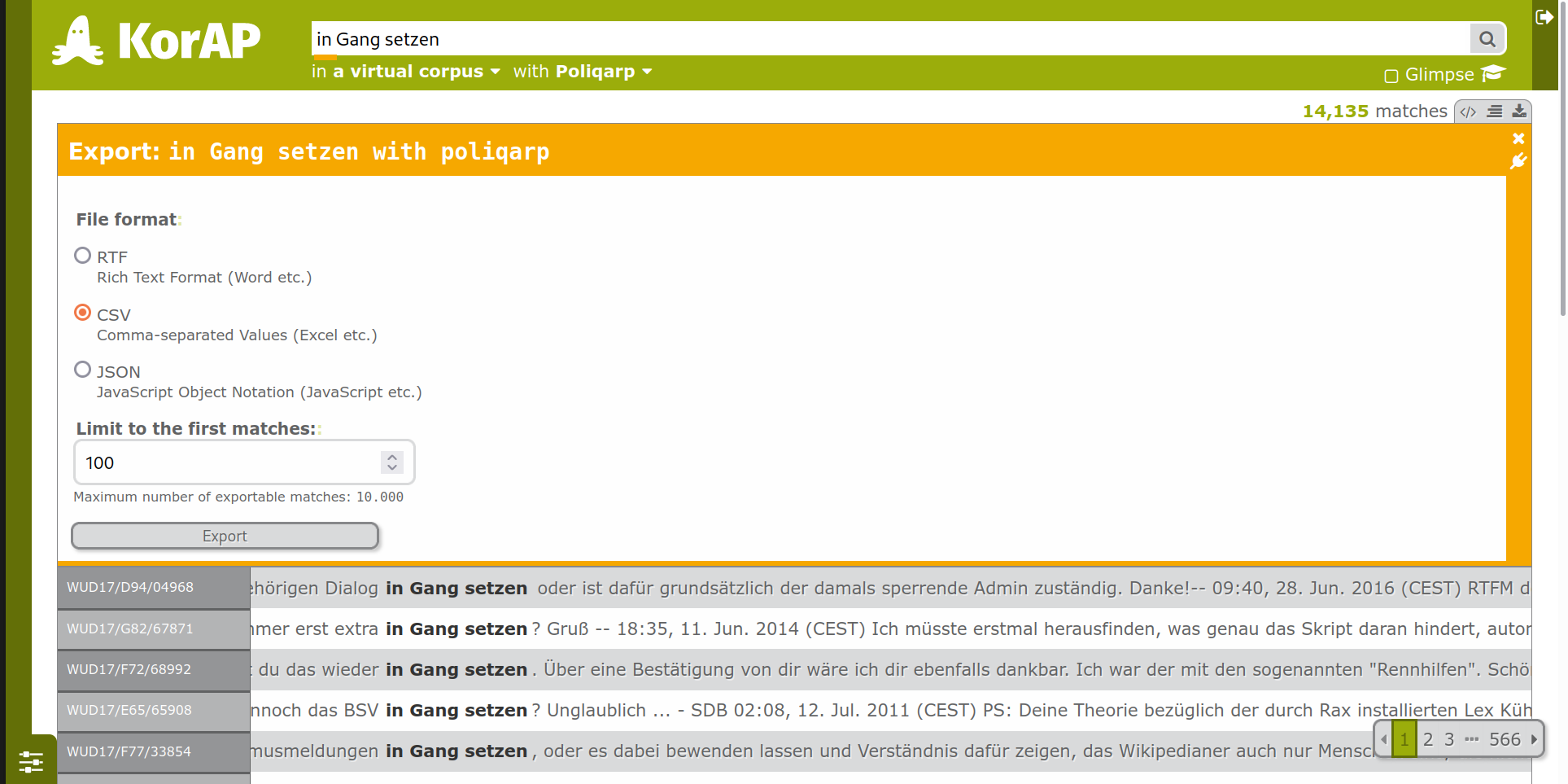
Glemm plugin (Inverse lemmatizer for German)
search for the whole inflection paradigm of gut (maximise recall...)
Level 3: multiple instances
when in doubt just run another platform / instance
-
it's hard to maintain multiple running platform instances
-
but it's impossible to create the one jack of all trades
-
with dynamical meta-configuration functions to switch between different corpora, authentication backends, …
-
-
we are running different platforms (COSMAS, KorAP, …)
-
and several instances of KorAP with different configurations
-
different authorization workflows
-
different corpora
-
on different hardware
-
-
most import application field now:
contrastive linguistic studies in the context of EuReCo
European Reference Corpus EuReCo
-
open initiative founded in 2013 by the IDS and the academies in Poland, Romania and Hungary (Kupietz et al. 2017)
-
to sustainably address the need for comparable corpora
-
re-using existing national and reference corpora,
-
by joining them just virtually
-
and defining virtual comparable sub-corpora dynamically based on metadata property distributions
-
Comparable CoRoLa/DeReKo corpus
just based on topic domain (according to DeReKo's top level taxonomy)
Composition by year of publication
not controlled, but also quite similar
Basic PTCND-idea translated to EuReCo
… build some infrastructure to use the data from where it is.
Just use multiple instances for CoRoLa and DeReKo
Same with HNC and DeReKo
also concerning the UI: simply put two windows side by side
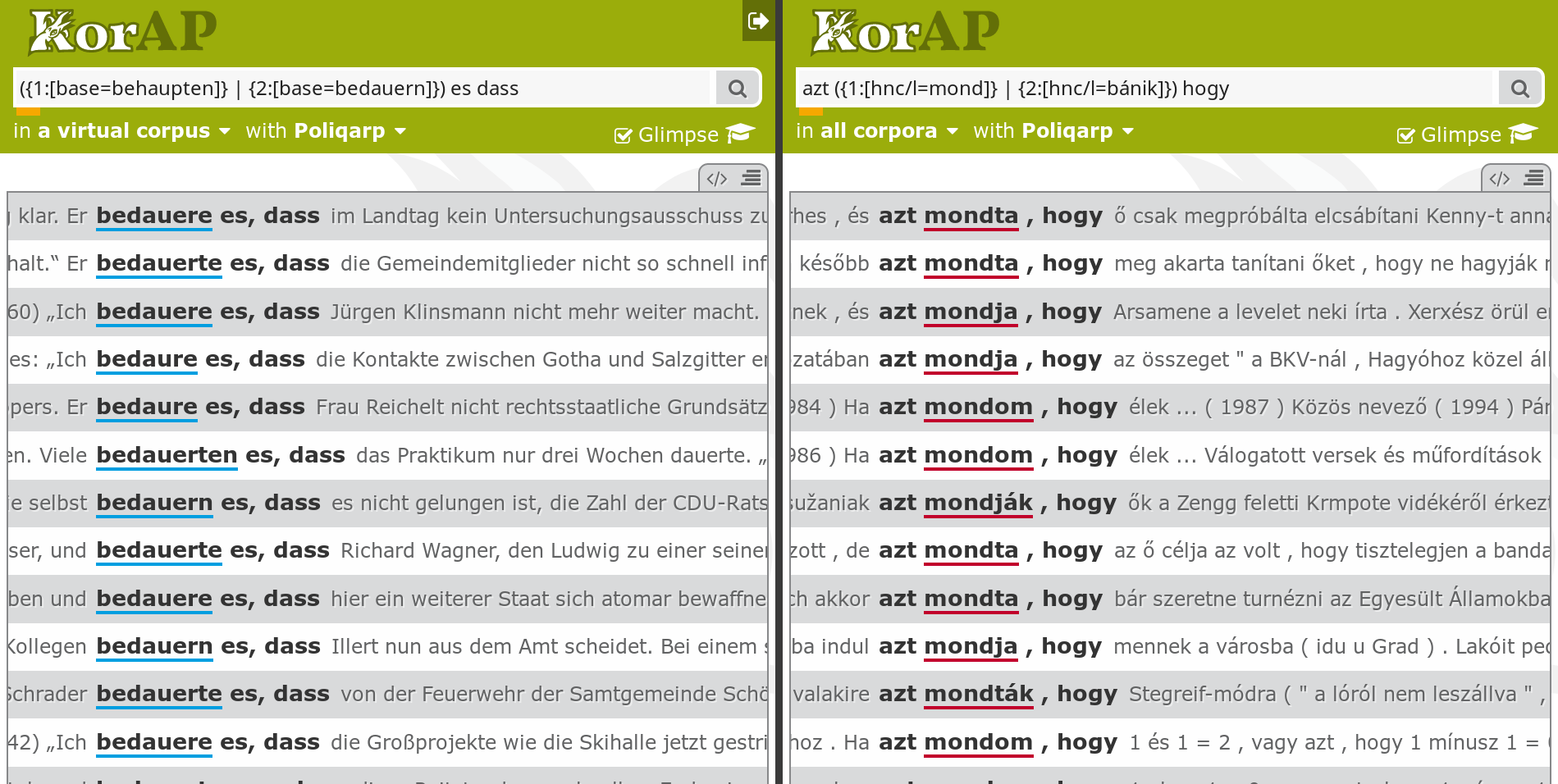
And use API libraries for actual contrastive studies
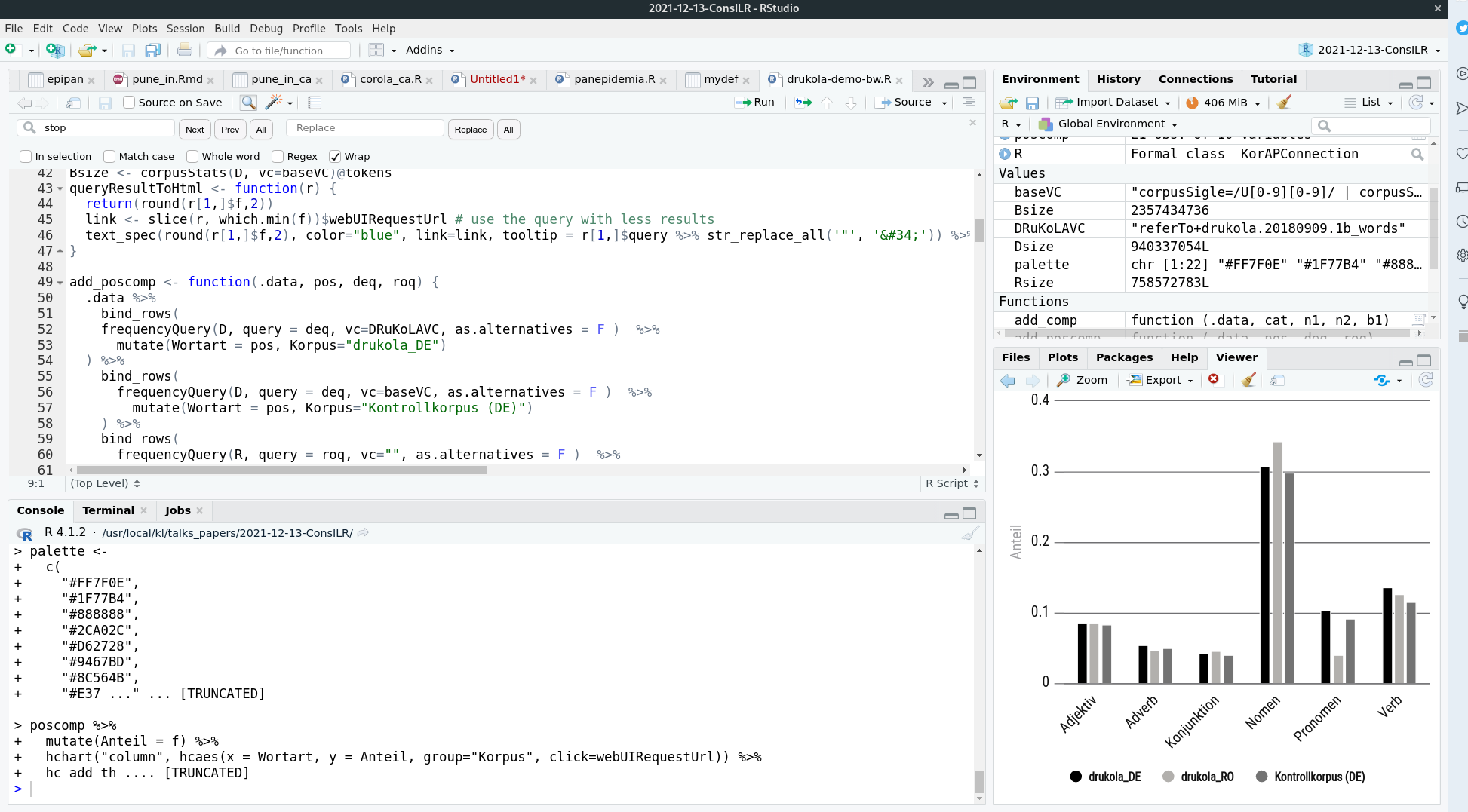
e.g. Comparison Romanian and German LVCs
(Kupietz & Trawínski, forthcoming)
| <pune> în <NN> / CoRoLa | ||
|---|---|---|
| NN | logDice | EN (~DeepL) |
| pericol | 11,16 | Danger |
| aplicare | 10,74 | Application |
| mișcare | 10,63 | Move |
| discuție | 10,07 | Discussion |
| funcțiune | 9,97 | Function |
| evidență | 9,64 | Highlight |
| practică | 8,95 | Practice |
| executare | 8,85 | Version |
| scenă | 8,81 | Scene |
| Vânzare | 8,51 | Sale |
| circulație | 8,44 | Circulation |
| valoare | 8,31 | Value |
| slujba | 8,24 | Job |
| lumină | 7,88 | Light |
| vedere | 7,26 | View |
| discuția | 7,11 | Discussion |
| JOC | 7,10 | Game |
| libertate | 7,04 | Freedom |
| relație | 6,87 | Relationship |
| balanță | 6,79 | Balance |
| situația | 6,55 | Situation |
| borcane | 6,48 | Glasses |
| serviciul | 6,41 | Service |
| umbră | 6,23 | Shadow |
| legătură | 6,20 | Link |
| primejdie | 6,13 | Emergency |
| posesie | 6,03 | Possession |
| față | 6,02 | Face |
| in <NN> <setzen> / vc_drukola | |
|---|---|
| <NN> | logDice |
| Gang | 10,84 |
| Szene | 10,59 |
| Brand | 10,12 |
| Kenntnis | 9,55 |
| Bewegung | 9,44 |
| Verbindung | 9,16 |
| Marsch | 9,07 |
| Kraft | 8,41 |
| Beziehung | 7,80 |
| Umlauf | 7,70 |
| Anführungszeichen | 7,40 |
| Flammen | 6,59 |
| Relation | 6,39 |
| Untersuchungshaft | 6,38 |
| Klammern | 6,12 |
| Betrieb | 5,92 |
| Stand | 5,90 |
| Erstaunen | 5,75 |
| Bezug | 5,51 |
| Vollzug | 5,13 |
| Anführungsstriche | 5,06 |
| Gänsefüßchen | 4,74 |
| Auslieferungshaft | 4,42 |
| Parallele | 4,39 |
| Vergleich | 4,38 |
| Verkehr | 4,28 |
| Pose | 4,15 |
| Positur | 4,10 |
More complex stuff more appropriate at API level
for now
-
contrastive studies still require lots of experimentation
-
applications heavily depend on properties of the used corpora
-
available metadata categories
-
POS annotations
-
-
but even more on their respective languages
-
some frequently used, popular features might rise to the UI
-
with the corresponding backend support
-
but probably nothing in the near future
-
Level 4: open source code contributions
-
let anyone create new features by suggesting source code extensions
-
apart from bug fixes, mainly aimed at larger projects
-
ideally avoiding forks
-
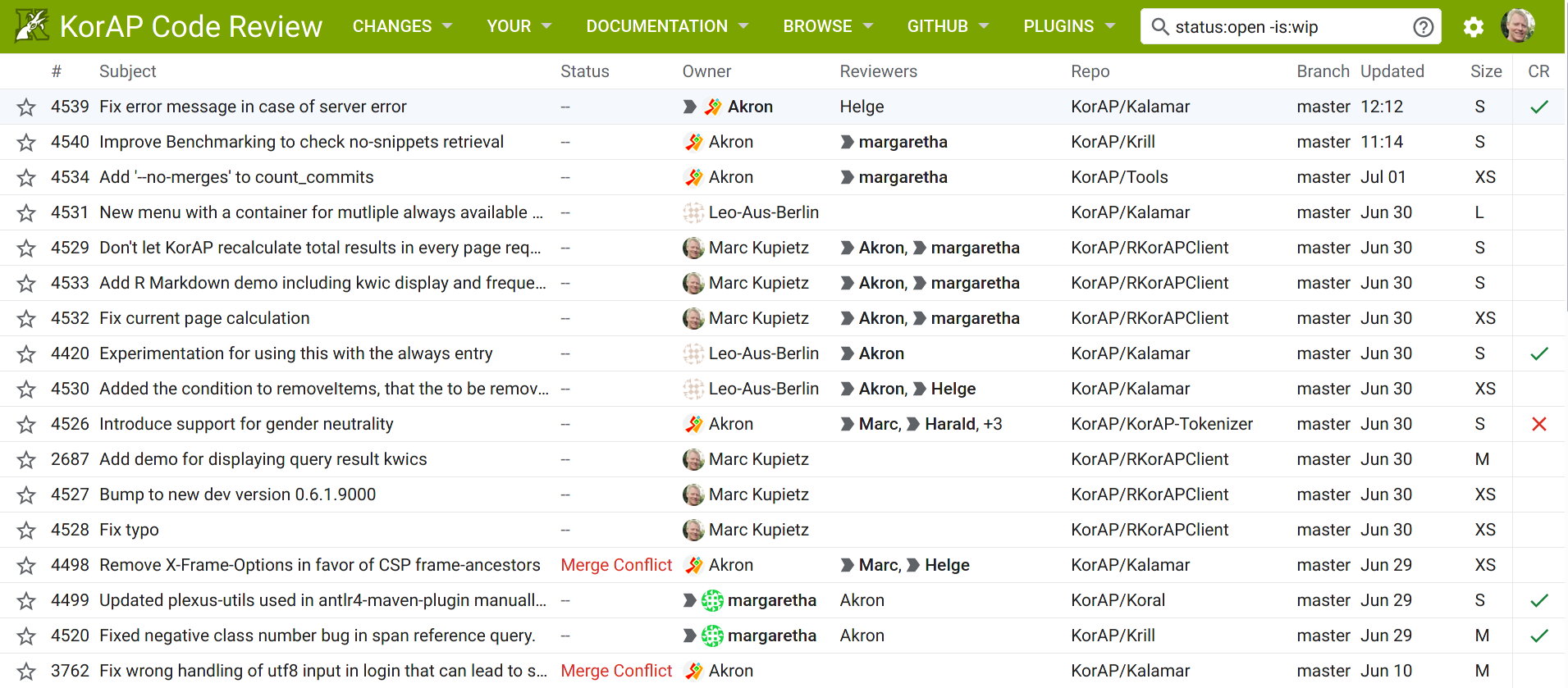
also to support external developers, we use Gerrit Code Review on top of git
-
use by Google, SAP, LibreOffice, Wikimedia, …
-
superior for discussing code contributions compared to GitHub pull requests
-
All KorAP modules on Github
most of them BSD-licensed
KorAP's Gerrit Code Review
Level 5: corpus level
put the computation near the data, manually
-
last resort if all other levels are not applicable
-
typical application scenarios
-
sophisticated corpus and quantitative linguistic applications
-
that require specialized language models
-
-
very costly, wrt.
-
expert staff
-
hardware use
-
-
only possible upon request with a kind of application
Typical workflow on the corpus level
-
users can choose between different corpus data formats
-
TEI I5
-
KorAP-XML
-
CoNLL-U
-
Metadata SQL-DB
-
-
user gets copyright-free sample data
-
adapts their code to the data
-
send their code in a common git repo
-
IDS staff applies the code and sends back the results
5. Preliminary Results & Conclusions
Levels of access summary
Preliminary Results
General observations after ~ 2 years
-
we have designed the model only partly like this
-
for the most part, it has gradually solidified and established itself over the last few years
-
almost all users inside and outside could easily be convinced that an approach like this makes sense
1: API level experiences
i.e. use of Python and R client libraries
-
by far the most popular and successful level
-
adopted by many power users of DeReKo
-
including the German Council for Orthography
-
more and more often included in teaching
-
also from the side of programming courses
-
-
manageable costs
RKorAPClient downloads / month
(normalized for CI-tests by subtracting ThreeWiseMonkeys dummy package)
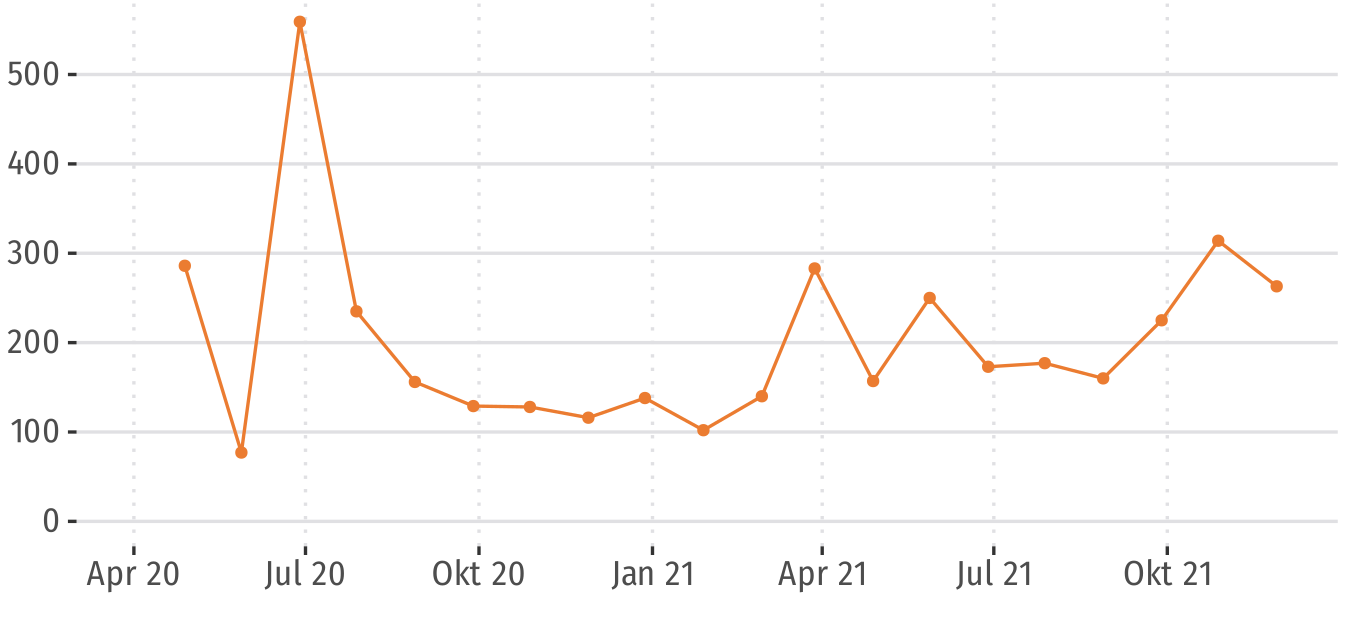
2: UI plugins
-
very early stage
-
more examples need
-
looking forward to first student project
3: multiple instances
-
for the everybody-runs-their-own-KorAP scenario:
-
multiple instances for multiple languages
-
quite perfect but some maintenance effort
-
-
for us running multiple KorAP instances
-
more DevOps automation urgently needed
-
4: open source contributions
-
still only a very small proportion of external code contributions
-
third-party funding for larger external projects apparently difficult
-
no fundings schemes for combinations of research software development with linguistic research
-
-
nevertheless very important level
-
also to be able to channelise wishes and demands
-
5: corpus level
(put the computation near the data manually)
-
could be mostly avoided by suggesting the API level
-
at least some of the cost intensive work could be carried out by the users themselves on the API level
-
-
very satisfied with the remaining projects
-
bottleneck currently rather hardware than staff
-
the procedure could perhaps be improved by switching to more formal cooperation applications
Conclusions
-
ptcntd and multi-staged approaches are the ways to go to make corpus data as actually usable a possible
-
our multi-staged model is probably not much more than a formalization of what we would be doing anyway
-
but the model seems to help us making the right decisions quickly
-
also concerning the level-raising of popular functionalities
-
-
it also seems to convince users and allows them to engage with one of the options on offer more easily
Thank you very much for your attention!
References
References
Bański, P., Fischer, P. M., Frick, E., Ketzan, E., Kupietz, M., Schnober, C., Schonefeld, O., Witt, A. (2012):
The New IDS Corpus Analysis Platform: Challenges and Prospects. In: Calzolari, N. et al. (eds.): Proceedings of the Eighth International Conference on Language Resources and Evaluation (LREC’12). Istanbul, Turkey, May 2012. European Language Resources Association (ELRA), 2012: 2905-2911.
Bański, P., Diewald, N., Hanl, M., Kupietz, M. and A. Witt (2014):
Access Control by Query Rewriting: the Case of KorAP. In: Proceedings of the 9th conference on the Language Resources and Evaluation Conference (LREC 2014), European Language Resources Association (ELRA), Reykjavik, Iceland, May 2014: 3817-3822.
Bingel, J. and Diewald, N. (2015):
KoralQuery – a General Corpus Query Protocol. In: Proceedings of the Workshop on Innovative Corpus Query and Visualization Tools at NODALIDA 2015, Vilnius, Lithuania, May 11-13, pp. 1-5.
Cosma, R., Cristea, D., Kupietz, M., Tufiş, D., Witt, A. (2016):
DRuKoLA – Towards Contrastive German-Romanian Research based on Comparable Corpora. In: Bański, P. et al. (eds.): 4th Workshop on Challenges in the Management of Large Corpora. Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC 2016), Portorož, Slowenien. Paris: European Language Resources Association (ELRA), 2016: 28-32.
Cristea, Dan/Diewald, Nils/Haja, Gabriela/Mărănduc, Cătălina/Barbu Mititelu, Verginica/Onofrei, Mihaela (2019):
How to find a shining needle in the haystack. Querying CoRoLa: solutions and perspectives. In: Cosma, Ruxandra/Kupietz, Marc (Hrsg.), On design, creation and use of the Reference Corpus of Contemporary Romanian and its analysis tools. CoRoLa, KorAP, DRuKoLA and EuReCo, Revue Roumaine de Linguistique, 64(3). Editura Academiei Române, Bucharest, Romania.
Diewald, Nils/Barbu Mititelu, Verginica/Kupietz, Marc (2019):
The KorAP user interface. Accessing CoRoLa via KorAP. In: Cosma, Ruxandra/Kupietz, Marc (Hrsg.): On design, creation and use of the Reference Corpus of Contemporary Romanian and its analysis tools. CoRoLa, KorAP, DRuKoLA and EuReCo. (= Revue Roumaine de Linguistique 64(3)). Bucureşti: Editura Academiei Române, 2019. S. 265-277. →IDS-Publikationsserver →Text
Diewald, Nils and Margaretha, Eliza (2016):
Krill: KorAP search and analysis engine. In: Journal for Language Technology and Computational Linguistics (JLCL), 31 (1). 63-80.
Gray, Jim (2004):
Distributed Computing Economics. In: Herbert A., Jones K.S. (eds) Computer Systems. Monographs in Computer Science. Springer, New York, NY
Kupietz, Marc / Diewald, Nils / Margaretha, Eliza (forthcoming):
Building paths to corpus data - A multi-level least effort and maximum return approach. In Fišer, Darja / Witt, Andreas (eds.): The CLARIN Book. DeGruyter (forthcoming 2022).
Kupietz, Marc / Trawiński, Beata (forthcoming):
Neue Perspektiven für kontrastive Korpuslinguistik: Das Europäische Referenzkorpus EuReCo. In: Akten des XIV. Kongresses der Internationalen Vereinigung für Germanische Sprach- und Literaturwissenschaft (IVG). Peter Lang (to appear in 2022)
Kupietz, Marc/Diewald, Nils/Trawiński, Beata/Cosma, Ruxandra/Cristea, Dan/Tufiş, Dan/Váradi, Tamás/Wöllstein, Angelika (2020):
Recent developments in the European Reference Corpus EuReCo. In: Granger, Sylviane/Lefer, Marie-Aude (Hrsg.): Translating and Comparing Languages: Corpus-based Insights. (= Corpora and Language in Use, Proceedings 6). Louvain-la-Neuve: Presses universitaires de Louvain, 2020. S. 257-273.
Kupietz, Marc/Diewald, Nils/Margaretha, Eliza (2020b):
RKorAPClient: An R Package for Accessing the German Reference Corpus DeReKo via KorAP. In: Calzolari, Nicoletta/Béchet, Frédéric/Blache, Philippe/Choukri, Khalid/Cieri, Christopher/Declerck, Thierry/Goggi, Sara/Isahara, Hitoshi/Maegaard, Bente/Mariani, Joseph/Mazo, Hélène/Moreno, Asuncion/Odijk, Jan/Piperidis, Stelios (Hrsg.): Proceedings of the 12th International Conference on Language Resources and Evaluation (LREC), May 11-16, 2020, Palais du Pharo, Marseille, France. Paris: European Language Resources Association, 2020. S. 7016-7021.
Kupietz, Marc/Diewald, Nils/Fankhauser, Peter (2018):
How to Get the Computation Near the Data: Improving data accessibility to, and reusability of analysis functions in corpus query platforms. In: Bański, Piotr/Kupietz, Marc/Barbaresi, Adrien/Biber, Hanno/Breiteneder, Evelyn/Clematide, Simon/Witt, Andreas (Hrsg.): Proceedings of the LREC 2018 Workshop “Challenges in the Management of Large Corpora (CMLC-6)”. 07 May 2018 – Miyazaki, Japan. Paris: ELRA. pp. 20-25.
Kupietz, Marc/Cosma, Ruxandra/Cristea, Dan/Diewald, Nils/Trawiński, Beata/Tufiş, Dan/Váradi, Tamás/Wöllstein, Angelika (2018b):
Recent developments in the European Reference Corpus (EuReCo). In: Granger, Sylviane/Lefer, Marie-Aude/Aguiar de Souza Penha Marion, Laura (eds.): Using Corpora in Contrastive and Translation Studies Conference (5th edition). Book of Abstract. Louvain-la-Neuve: CECL, 2018. pp.. 101-103.
Kupietz, M., Belica, C., Keibel, H. and Witt, A. (2010):
The German Reference Corpus DeReKo: A primordial sample for linguistic research. In: Calzolari, N. et al. (eds.): Proceedings of LREC 2010. 1848-1854.
Kupietz, M., Lüngen, H., Bański, P. and Belica, C. (2014):
Maximizing the Potential of Very Large Corpora. In: Kupietz, M., Biber, H., Lüngen, H., Bański, P., Breiteneder, E., Mörth, K., Witt, A., Takhsha, J. (eds.): Proceedings of the LREC-2014-Workshop Challenges in the Management of Large Corpora (CMLC2). Reykjavik: ELRA, 1–6.
Kupietz, M., Witt, A., Bański, P., Tufiş, D., Cristea, D., Váradi, T. (2017):
EuReCo – Joining Forces for a European Reference Corpus as a sustainable base for cross-linguistic research. In: Bański, P. et al. (eds.): Proceedings of the Workshop on Challenges in the Management of Large Corpora and Big Data and Natural Language Processing (CMLC-5+BigNLP) 2017. Birmingham, 24 July 2017. Mannheim: Institut für Deutsche Sprache, 2017: 15-19.
Váradi, T. (2002):
The Hungarian National Corpus. In Rodríguez, M. & Araujo, C. (eds) Proceedings of LREC 2002, Las Palmas / Paris: ELRA, 385–389.