DeutUng in the Context of the European Reference Corpus EuReCo
DeutUng final workshop, 16.12.2021, Mannheim / online
1. Introduction
Background
-
importance of corpora for linguistic research, both in single language as well as in cross-linguistic contexts
-
the number of linguistic studies based on corpus data is increasing
-
the number (and size) of corpora is growing
-
linguists are often faced with a choice between several different types of corpora
-
options available for cross-linguistic research →
Corpora for language comparison
Kupietz et al. (2020), Trawiński and Kupietz (2021)
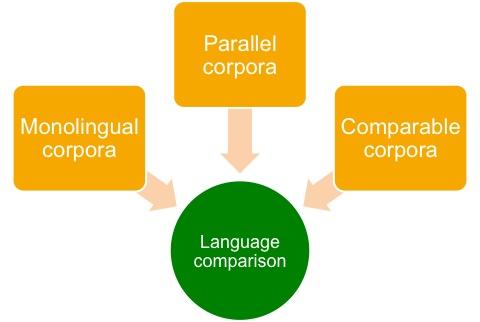
Corpora for language comparison
Kupietz et al. (2020), Trawiński and Kupietz (2021)
2. Monolingual corpora
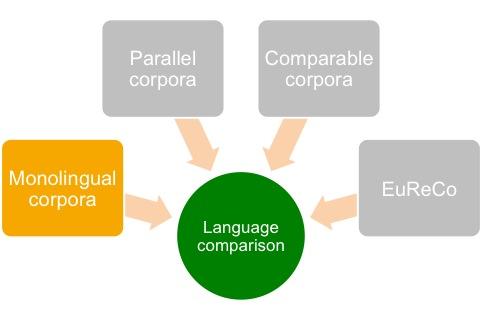
Monolingual corpora
-
texts in only one language
-
usually in the original language, therefore of high quality
-
usually linguistically annotated (language-specific)
-
examples of large national reference corpora:
-
DeReKo , ANC, BNC, CNC, NKJP, RNC, CoRoLa, HNC
-
-
frequently used in cross-linguistic research
-
Augustin (2017), Taborek (2018, 2020), GDE etc.
-
Methodological questions
-
To what extent are the results of studies based on monolingual corpora comparable?
-
The results are comparable at a meta-level (theoretical level / level of generalizations).
-
At the empirical level (data level) they are less comparable.
-
Reason: Diversity of monolingual corpora (Trawiński and Kupietz 2021)
-
Conclusion: Monolingual corpora
-
low matching with regard to size, text types, topics, etc. (also morphosyntactic annotation)
-

-
but high linguistic quality
-

3. Parallel corpora
Parallel corpora
-
Parallel corpora consist of original texts in one language (source language) and their translations in other languages (target languages).
-
Texts in all languages aligned at sentence level
-
partially linguistically annotated (mainly language-specific annotation)
-
large multilingual parallel corpora:
-
OPUS, Europarl, InterCorp
-
Advantages of parallel corpora
-
Parallel data: sequences of linguistic units (words, sentences) in two or more languages,
-
which are translation equivalents of each other and as such convey the same meaning
-
are used in the same contexts
-
occur in the same text types from the same time periods etc.
-
-
perfect basis for identifying functional equivalence between linguistic structures (James 1980, Chesterman 1998) → tertium comparationis
-
allow to gain insights into cross-linguistic similarities and differences that might be overlooked when working with monolingual corpora
Linguistic work
contrastive, typological, translational
-
Johansson (2007), Altenberg and Granger (2002), Granger (2010), Languages in Contrast (International Journal for Contrastive Linguistics) etc.
-
Cysouw and Wälchli (2007) etc.
-
Granger et al (2003) etc.
Problems with parallel corpora
-
relatively small size
-
the more languages, the smaller and less differentiated is the corpus
-
-
unbalanced in terms of original texts and translations
-
specific properties of translations (a third code)
-
Laviosa (1998), Baker (1995), Teich (2003): shining through, normalization, simplification etc.
-
Conclusion: Parallel corpora
-
high comparability in terms of size and content (but not in terms of morphosyntactic annotation)
-
-
lower quality of the linguistic material
-


4. Comparable corpora
Need for comparable corpora
-
monolingual and parallel corpora alone are not suitable for finer grained linguistic research
-
because they lack either comparability or linguistic quality
-
-
possible remedy:
-
use a combination of parallel and monolingual corpora
-
disadvantages:
-
(quantitative) findings not directly assessable
-
-
-
desideratum: comparable corpora of high quality
-

Comparable corpus
Definition (McEnery & Xiao 2007)
-
"a comparable corpus can be defined as a corpus containing components that are collected using the same sampling frame and similar balance and representativeness [...], e.g. the same proportions of the texts of the same genres in the same domains in a range of different languages in the same sampling period"
Actual or Practical comparability
is also relevant, we think
-

-
through rich metadata
-
which should be mappable among the corpora
-
-
through linguistic annotations
-
ideally also mappable e.g. by using Universal Dependencies annotations
-
-
through appropriate (and common) analysis tools
-
which make all these possibilities usable in the first place
-
Available general comparable corpora
... that include German
-
currently only Aranea - family of comparable gigaword web corpora (Benko 2014)
-
great and readily usable via NSkE
-
but composition not controlled
-

-
-
in future: International Comparable Corpus (ICC)
(Kirk et al. 2017, Čermáková et al. 2021).-
approach complementary to EuReCo : using small corpora with controlled composition along the lines of the ICE (Greenbaum 1991)
-
ideally joined with EuReCo in the future
-
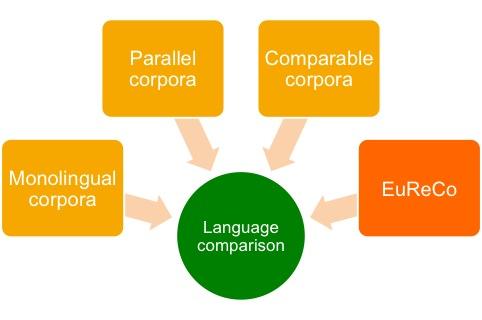
5. EuReCo
EuReCo - European Reference Corpus
-
open initiative founded in 2013 by the academies in Poland, Romania and Hungary and the IDS
-
pilot projects (Humboldt Research Group Linkage Programmes):
-
DRuKoLA: Romanian-German (2016-2018): CoRoLa (Tufiş et al. 2019).
-
DeutUng: Hungarian-German (2017-2021): HNC (Váradi 2002)
-
-
EuReCo is based on two core assumptions …
1. dedicated comparable corpora econom. infeasible
-
even monolingual universal corpora often cannot be permanently maintained / extended
-
dedicated multilingual comparable corpora would multiply the already unrealistic costs
-
dedicated comparable corpora cannot be built from scratch and maintained sustainably
EuReCo's approach
-
use the existing national and reference corpora
-
which are maintained and sometimes extended by sustainable institutions
-
instead of trying to build new ones
Expected benefits of the EuReCo approach
-
more economical, scalable and sustainable
-
especially since one can also benefit from ongoing and future extensions and improvements of these corpora
-
-
high linguistic quality and sufficient size to be expected in national corpora
-

2. general comparability is not achievable
-
corpora with reasonable size and diversity cannot be perfectly comparable in general
-
there will always be a criterion against which the corpora are not comparable
-
whether an unequal distribution with regard to such a variable is relevant depends on the specific research question
-
-
generally comparable corpora are not a reasonable goal
2b. General representativeness is not possible
-
more important: single language corpora cannot be generally representative
-
since population=language is not generally definable
-
whether a corpus is sufficiently representative depends on the research question and the language domain
-
-
generally comparable and representative corpora are not meaningful objectives
EuReCo: dynamically definable, virt. comparable corpora!
In analogy to DeReKo's ›primordial sample‹ approach (Kupietz 2016)
-
EuReCo users are invited to ...
-
use predefined (comparable) corpora or
-
define themselves corpora that are
suitably representative and comparable
with regard to their respective research question
Basic approach
(Cosma et al. 2016) cf. McEnery & Xiao (2007).
-
draw sub-corpora from the monolingual corpora
-
so that they have similar token distributions with respect to metadata variables like:
-
topic area
-
text type
-
publication date
-
…
-
Refinement: Iterative (and question specific)
for gradual approximation to sufficient comparability
-
begin as described above
-
carry out comparative case studies
-
if the findings appear to be artefacts of comparability criteria, refine the mapping and start again with 2
-

In principle possible with KorAP-VC-Builder
but not yet practicable due to missing downsampling function

Comparable CoRoLa/DeReKo corpus
just based on token distribution wrt topic domain (according to DeReKo's top level
taxonomy)
Composition by year of publication
was not controlled, but is also quite similar
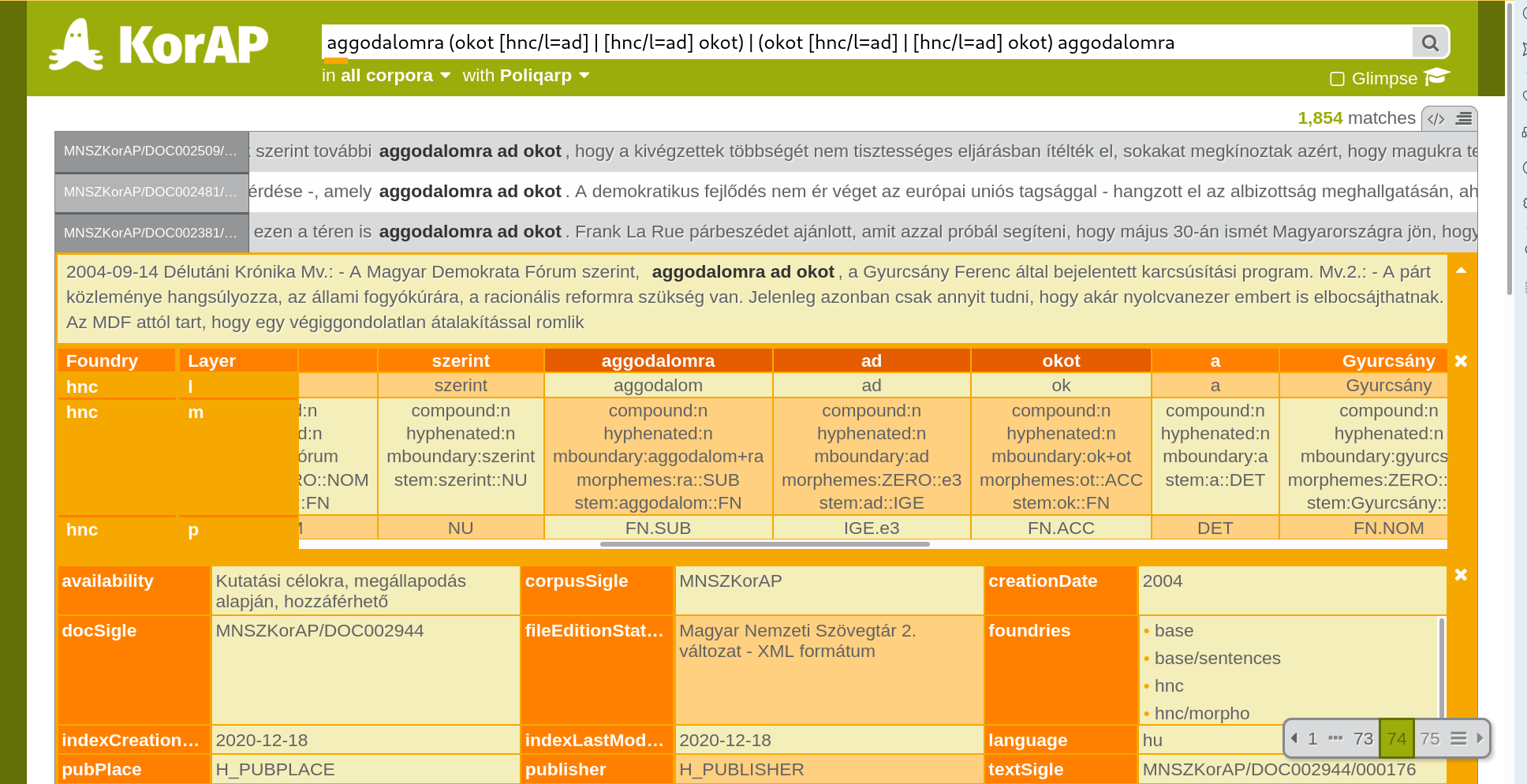
Comparable corpus usable with KorAP
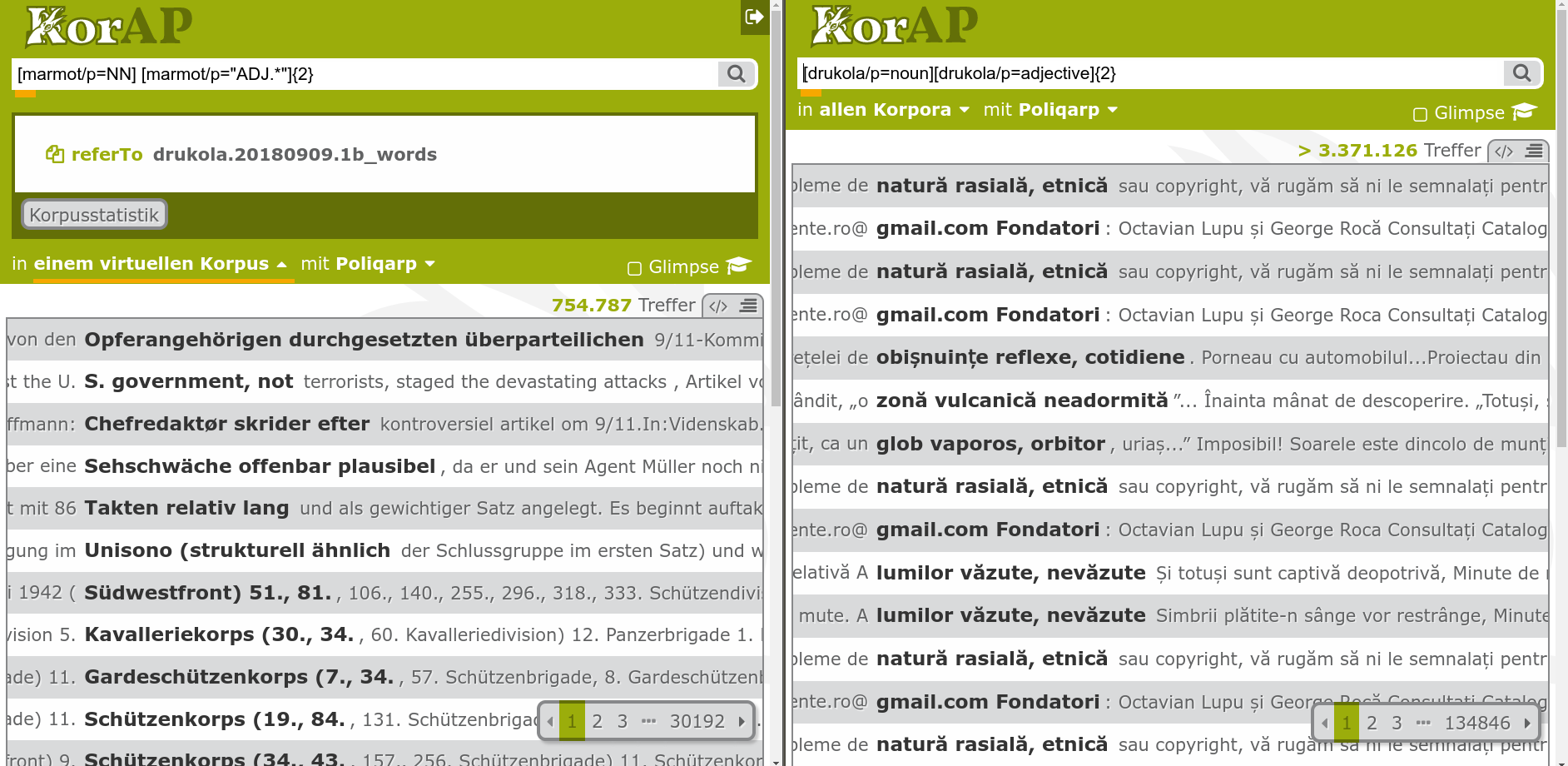
Also HNC fully queryable via KorAP
https://korap.nlp.nytud.hu/ – but so far without controlled comparability
6. Current Work in progress
Comparison of syntagmatic patterns
and their contexts of use in German, Romanian & Hungarian
-
using collocation analysis
-
to investigate e.g. light verb constructions (cf. Taborek 2018)
-
depending on text-external variables
-
-
with manifold 'secondary' objectives:
-
investigate comparability criteria, consequences …
-
identify helpful extensions for KorAP
-
further develop the methodology to identify interesting syntagm. patterns (Belica & Perkuhn 2015)
-
Collocation analysis with KorAP's R library
not yet supported in the UI, but very flexible with R library (Kupietz et al. 2020b)
library(RKorAPClient)
corola <- new("KorAPConnection", KorAPUrl = "https://korap.racai.ro/")
dereko <- new("KorAPConnection", verbose = T)
vc_drukola <- "referTo drukola.20180909.1b_words"
in_NN_setzen <- collocationAnalysis(
dereko,
node = "focus(in [tt/p=NN] {[tt/l=setzen]})",
vc = vc_drukola,
leftContextSize = 1, # refers to {} in focus()
rightContextSize = 0
)
pune_in_NN <- collocationAnalysis(
corola,
node = "focus({[drukola/l=pune] în} [drukola/p=noun])",
leftContextSize = 0,
rightContextSize = 1
)
Example LVC comparison Romanian-German
Kupietz & Trawiński (forthcoming)
| <pune> în <NN> / CoRoLa | ||
|---|---|---|
| NN | logDice | EN (~DeepL) |
| pericol | 11,16 | Danger |
| aplicare | 10,74 | Application |
| mișcare | 10,63 | Move |
| discuție | 10,07 | Discussion |
| funcțiune | 9,97 | Function |
| evidență | 9,64 | Highlight |
| practică | 8,95 | Practice |
| executare | 8,85 | Version |
| scenă | 8,81 | Scene |
| Vânzare | 8,51 | Sale |
| circulație | 8,44 | Circulation |
| valoare | 8,31 | Value |
| slujba | 8,24 | Job |
| lumină | 7,88 | Light |
| vedere | 7,26 | View |
| discuția | 7,11 | Discussion |
| JOC | 7,10 | Game |
| libertate | 7,04 | Freedom |
| relație | 6,87 | Relationship |
| balanță | 6,79 | Balance |
| situația | 6,55 | Situation |
| borcane | 6,48 | Glasses |
| serviciul | 6,41 | Service |
| umbră | 6,23 | Shadow |
| legătură | 6,20 | Link |
| primejdie | 6,13 | Emergency |
| posesie | 6,03 | Possession |
| față | 6,02 | Face |
| in <NN> <setzen> / vc_drukola | |
|---|---|
| <NN> | logDice |
| Gang | 10,84 |
| Szene | 10,59 |
| Brand | 10,12 |
| Kenntnis | 9,55 |
| Bewegung | 9,44 |
| Verbindung | 9,16 |
| Marsch | 9,07 |
| Kraft | 8,41 |
| Beziehung | 7,80 |
| Umlauf | 7,70 |
| Anführungszeichen | 7,40 |
| Flammen | 6,59 |
| Relation | 6,39 |
| Untersuchungshaft | 6,38 |
| Klammern | 6,12 |
| Betrieb | 5,92 |
| Stand | 5,90 |
| Erstaunen | 5,75 |
| Bezug | 5,51 |
| Vollzug | 5,13 |
| Anführungsstriche | 5,06 |
| Gänsefüßchen | 4,74 |
| Auslieferungshaft | 4,42 |
| Parallele | 4,39 |
| Vergleich | 4,38 |
| Verkehr | 4,28 |
| Pose | 4,15 |
| Positur | 4,10 |
➞ Cohesion strengths strongly dependent on domain
Collocate rankings of "pune în ..." in domain = / ≠ law: ϱ(N=39) << 0.58
| Domain = Law | |
|---|---|
| pune în ... | logDice |
| pericol | 11,79 |
| mișcare | 11,10 |
| aplicare | 10,76 |
| funcțiune | 10,58 |
| discuție | 10,54 |
| executare | 9,79 |
| liberă | 9,07 |
| Vânzare | 8,78 |
| circulație | 8,71 |
| discuția | 8,05 |
| vedere | 8,05 |
| practică | 8,01 |
| întârziere | 7,56 |
| evidență | 7,32 |
| libertate | 7,18 |
| corespondență | 7,16 |
| posesie | 6,86 |
| vînzare | 6,77 |
| serviciul | 6,73 |
| valoare | 6,69 |
| echivalență | 6,60 |
| dezbaterea | 6,29 |
| sarcina | 6,27 |
| posesia | 6,09 |
| decbatere | 6,00 |
| plicuri | 5,94 |
| primejdie | 5,87 |
| comun | 5,76 |
| Domain ≠ Law | |
|---|---|
| pune în ... | logDice |
| aplicare | 11,09 |
| evidență | 10,92 |
| pericol | 9,96 |
| practică | 9,61 |
| discuție | 9,59 |
| mișcare | 9,54 |
| scenă | 9,41 |
| valoare | 9,25 |
| funcțiune | 8,87 |
| circulație | 8,70 |
| slujba | 8,69 |
| Vânzare | 8,49 |
| lumină | 8,38 |
| situația | 8,20 |
| relație | 7,75 |
| JOC | 7,59 |
| balanță | 7,16 |
| libertate | 7,14 |
| gardă | 7,02 |
| primejdie | 6,90 |
| umbră | 6,86 |
| = | 6,79 |
| contact | 6,69 |
| dificultate | 6,67 |
| pagină | 6,64 |
| gând | 6,54 |
| legătură | 6,47 |
| față | 6,46 |
Collocation analysis with HNC
to identify LVC with hoz (=bring) and nouns in sublative or illative
hulvc <- function(q, leftContextSize, rightContextSize) {
hnc %>%
collocationAnalysis(
q,
leftContextSize = leftContextSize,
rightContextSize = rightContextSize,
exactFrequencies = TRUE,
withinSpan = "",
maxRecurse = 0,
searchHitsSampleLimit = 1000,
topCollocatesLimit = 30
)
}
hoz_left <- hulvc(
'focus([hnc/p="FN.(SUB|ILL)"] {[hnc/l=hoz]})',
leftContextSize = 1,
rightContextSize = 0
)
hoz_right <- hulvc(
'focus({[hnc/l=hoz]} [hnc/p="FN.(SUB|ILL)"])',
leftContextSize = 0,
rightContextSize = 1
)
hoz <- hoz_left %>% bind_rows(hoz_right) %>%
arrange(desc(logDice))
Light Verb Constructions in Hungarian
hoz (=bring) with noun in sublative or illative – focus([hnc/p="FN.(SUB|ILL)"] {[hnc/l=hoz]})
Larger synt. patterns by »recursive collocation analysis«
hoz (=bring) with recursion depth=2 (sorted by logDice)
Preliminary meta findings
-
when comparing syntagmatic patterns, the corpus composition itself can play a greater role than comparability
-
corpus access via scripts is essential
-
for reproducible results which are essential not only in the iterative corpus refinements
-
but for all analyses consisting of multiple steps
-
for custom-tailored visualizations
-
-
practical comparability is currently more essential than ›theoretical‹ comparability
Desirable Improvements
-
HNC-KorAP-integration: we need more metadata
-
to define comparable corpora
-
to detect dependencies on text external variables
-
but: some great practical comparability is already achieved
just by the HNC/KorAP integration
-
-
KorAP
-
access to token annotations should be supported by client libraries
-
lemma access essential for agglutinative languages
-
-
7. Distributed Comparable Corpora
KorAP Support for EuReCo
-
VC for virtual comparable corpora already mentioned
-
support for
-
arbitrary metadata
-
arbitrary annotations
-
token-bound, hierarchical, relational
-
-
different query languages (Bingel & Diewald 2015)
-
arbitrary licences (Bański et al 2014)
-
-
But: Focus on DeReKo and limited resources
Levels of Access
Kupietz et al. (forthcoming)
- 0
- User Interface
-
the web user interface (Diewald et al. 2019)
-
- 1
- Web Service API
-
accessible directly or via client libraries (Kupietz et al 2020b)
-
- 2
- Plugin
-
user interface plugins
-
- 3
- Instance
-
independent access by fully customized installations
-
- 4
- Open Source
-
new features by source code contributions
-
- 5
- Corpus
-
direct access to corpus data (without KorAP system)
-
Plugin Level
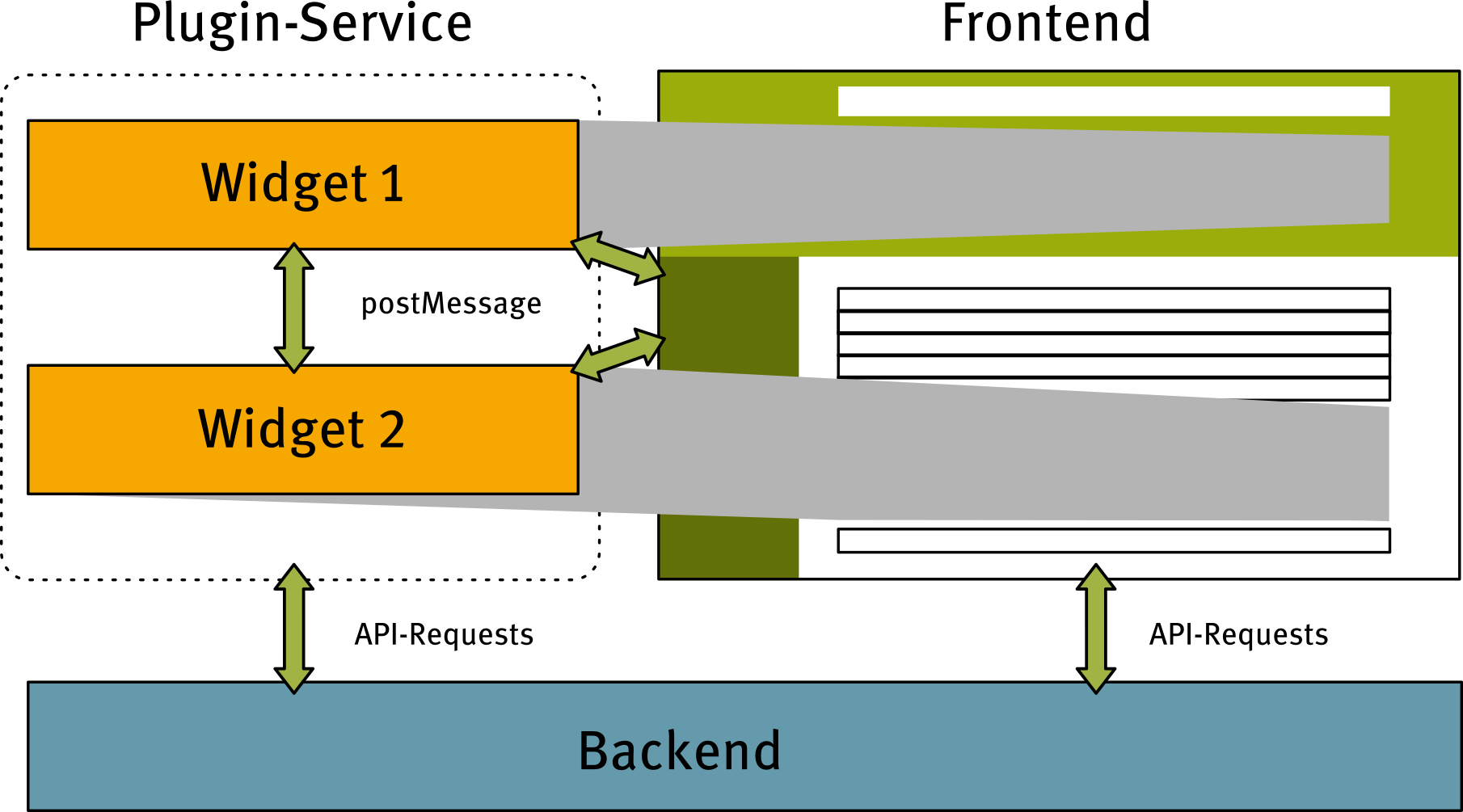
Plugin Level
Functional areas of the UI
-
search input
-
e.g. lemma expansion
-
-
definition of virtual corpora
-
e.g. corpus visualization
-
-
search results
-
e.g. export
-
-
individual matches
-
e.g. annotation visualizations
-
-
…
Next steps in KorAP development
-
extension and publication of core functionalities
(currently only available via API client libraries)-
e.g. sorting, grouping, distribution
-
-
establishing plugin interfaces
-
publication of plugins
8. Conclusion and outlook
Conclusion
-
we would like to have comparable corpora:
-
-
EuReCo offers a realistic approach to achieve this
-
by virtually joining existing large corpora
-
by means of user-defined, dynamically constructable comparable corpora
-
by providing the required sustainable research platform
-

Outlook
Next EuReCo steps
-
integrate further large corpora
-
we are currently working on the NKJP!
-
-
continue the KorAP development
-
especially also the client libraries
-
-
continue working on ICC and its Integration
Thank you very much for your attention!
References
Augustin, Hagen (2017):
Verschmelzung von Präpositionen und Artikel. Eine kontrastive Analyse zum Deutschen und Italienischen. Reihe: Konvergenz und Divergenz 6.
Baker, Mona (1995). Corpora in translation studies: An overview and some
suggestions for future research, Target 7(2), 223-243.
Bański, Piotr/Bingel, Joachim/Diewald, Nils/Frick, Elena/Hanl, Michael/Kupietz, Marc/Pęzik, Piotr/Schnober, Carsten/Witt, Andreas (2013):
KorAP: the new corpus analysis platform at IDS Mannheim. In: Vetulani, Zygmunt/Uszkoreit, Hans (eds.): Human Language Technologies as a Challenge for Computer Science and Linguistics. Proceedings of the 6th Language and Technology Conference. S. 586-587 - Poznań: Fundacja Uniwersytetu im. A., 2013.
Bański, Piotr/Diewald, Nils/Hanl, Michael/Kupietz, Marc/Witt, Andreas (2014):
Access Control by Query Rewriting: the Case of KorAP, In: Proceedings of the 9th conference on the Language Resources and Evaluation Conference (LREC 2014). European Language Resources Association (ELRA), Mai 2014, Reykjavic, Iceland, S. 3817–3822.
Belica, Cyril & Perkuhn, Rainer (2015):
Feste Wortgruppen/Phraseologie I: Kollokationen und syntagmatische Muster. In U. Haß & P. Storjohann (Hrsg..), Handbuch Wort und Wortschatz (pp. 201-225). Berlin, München, Boston: De Gruyter. https://doi.org/10.1515/9783110296013-009
Benko, Vladimír (2014):
Aranea: Yet Another Family of (Comparable) Web Corpora. In Petr Sojka, Aleš Horák, Ivan Kopeček and Karel Pala (Eds.): Text, Speech and Dialogue. 17th International Conference, TSD 2014, Brno, Czech Republic, September 8-12, 2014. Proceedings. LNCS 8655. Springer International Publishing Switzerland, 2014. pp. 257-264. ISBN: 978-3-319-10815-5 (Print), 978-3-319-10816-2 (Online). BibTeX PDF
Bingel, Joachim/Diewald, Nils (2015):
KoralQuery – a General Corpus Query Protocol. In: Proceedings of the Workshop on Innovative Corpus Query and Visualization Tools at NODALIDA 2015. 11.–13. Mai 2015, Vilnius, Lithuania, S. 1–5.
Borin, Lars/Forsberg, Markus/Roxendal, Johan (2012):
Korp – the corpus infrastructure of Språkbanken. In Proceedings of LREC 2012. Istanbul: Elra, 474–478
Brandt, Patrick unter Mitwirkung von Felix Bildhauer (2019):
Alternation von zu- und dass- Komplementen: Kontrolle, Korpus, und Grammatik. In: Fuß, Eric/Konopka, Marek/Wöllstein, Angelika. Grammatik im Korpus. Korpuslinguistisch-statistische Analysen morphosyntaktischer Variationsphänomene. Tübingen: Narr.
Brandt, Patrick/Trawiński, Beata/Wöllstein, Angelika (2017):
(Anti-)Control in German: Evidence from Comparative, Corpus- and Psycholinguistic Studies. In: Linguistische Berichte (Sonderheft). Hamburg: Buske.
Čermáková, A., Jantunen, J., Jauhiainen, T., Kirk, J., Křen, M., Kupietz, M., & Uí Dhonnchadha, E. (2021):
The International Comparable Corpus: Challenges in building multilingual spoken and written comparable corpora. Research in Corpus Linguistics, 9(1), 89-103.
Chesterman, Andrew (1998):
Contrastive Functional Analysis. Amsterdam/Philadelphia: John Benjamins Publishing Company.
Cosma, Ruxandra/Cristea, Dan/Kupietz, Marc/Tufiş, Dan/Witt, Andreas (2016):
DRuKoLA – Towards Contrastive German-Romanian Research based on Comparable Corpora. In: Bański, Piotr/Barbaresi, Adrien/Biber, Hanno/Breiteneder, Evelyn/Clematide, Simon/Kupietz, Marc/Lüngen, Harald/Witt, Andreas: 4th Workshop on Challenges in the Management of Large Corpora. Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC 2016), Portorož, Slowenien. Paris: European Language Resources Association (ELRA), 2016. pp 28-32.
Cysouw M./Wälchli B. (2007):
Parallel texts: using translational equivalents in linguistic typology. STUF - Sprachtypologie und Universalienforschung 60(2), 95–99.
Diewald, Nils/Barbu Mititelu, Verginica/Kupietz, Marc (2019):
The KorAP user interface. Accessing CoRoLa via KorAP. In: Cosma, Ruxandra/Kupietz, Marc (Hrsg.), On design, creation and use of the Reference Corpus of Contemporary Romanian and its analysis tools. CoRoLa, KorAP, DRuKoLA and EuReCo, Revue Roumaine de Linguistique, 64(3). Editura Academiei Române, Bucharest, Romania.
Gîfu, D., Moruz, A., Bolea, C., Bibiri, A. & Mitrofan, M. (2019):
The Methodology of Building CoRoLa. Revue roumaine de linguistique (3), 241-253.
Granger, S./Lerot, J./Petch-Tyson, S. (Eds.) (2003):
Corpus-based Approaches to Contrastive Linguistics and Translation Studies. Amsterdam / Atlanta: Rodopi.
Granger, S. (2010):
Comparable and translation corpora in cross-linguistic research. Design, analysis and applications. Journal of Shanghai Jiaotong University.
Gray, Jim (2003):
Distributed Computing Economics. Technical Report MSR-TR-2003-24, Microsoft Research.
Greenbaum, Sidney (1991):
ICE: The international corpus of English. English Today, 7(4), 3-7.
Gunkel, Lutz / Murelli, Adriano / Schlotthauer, Susan / Wiese, Bernd / Zifonun, Gisela (2017):
Grammatik des Deutschen im europäischen Vergleich – Das Nominal. Unter Mitarb. v. Günther, Christine / Hoberg, Ursula. Reihe: Schriften des Instituts für Deutsche Sprache 14.
Hartmann/Mucha/Trawiński/Wöllstein (in Vorbereitung):
Antikontrolle und Satzwertigkeit. In Beata Trawinski und Angelika Wöllstein (ed.): Perspektiven im Sprachvergleich. Pilotstudien zu einer Grammatik des Deutschen im Europäischen Vergleich. Reihe: Konvergenz und Divergenz. De Gruyter.
Hartmann, J. M., Schlotthauer, S., Trawiński, B. & Wöllstein, A. (2017):
Sprachvergleich: Einblicke in die aktuelle kontrastive Forschung am IDS: Nominal- und Verbgrammatik. Presentation at the Kick-off of the project DeutUng, 19.10.2017, University of Szeged (Hungary).
James, Carl (1980):
Contrastive Analysis. London: Longman.
Johansson, S. (1999):
Corpora and contrastive studies. In P. Pietilä & O-P. Salo (Hrgs.) Multiple Languages – Multiple Perspectives. AFinLA Yearbook 1999 / No. 57, 116-125.
Johansson, S. (2007):
Seeing through multilingual corpora. On the use of corpora in contrastive studies. Amsterdam: Benjamins.
Kirk, John/Čermáková, Anna (2017):
From ICE to ICC: The new International Comparable Corpus. In Bański et al. (eds.): Proceedings of the Workshop on Challenges in the Management of Large Corpora and Big Data and Natural Language Processing (CMLC-5+BigNLP) 2017 including the papers from the Web-as-Corpus (WAC-XI) guest section
Koehn, Philipp (2005):
Europarl: A Parallel Corpus for Statistical Machine Translation. MT Summit 2005.
Kupietz, Marc (2016):
Constructing a Corpus. In: Durkin, Philip: The Oxford Handbook of Lexicography. (= Oxford handbooks in linguistics). Oxford: Oxford University Press, 2016. S. 62-75.
Kupietz, Marc / Trawiński, Beata (forthcoming):
Neue Perspektiven für kontrastive Korpuslinguistik: Das Europäische Referenzkorpus EuReCo. In: Akten des XIV. Kongresses der Internationalen Vereinigung für Germanische Sprach- und Literaturwissenschaft (IVG). Peter Lang (to appear in 2022)
Kupietz, Marc / Diewald, Nils / Margaretha, Eliza (forthcoming):
Building paths to corpus data - A multi-level least effort and maximum return approach. In Fišer, Darja / Witt, Andreas (eds.): The CLARIN Book. DeGruyter (forthcoming 2022).
Kupietz, Marc/Belica, Cyril/Keibel, Holger/Witt, Andreas (2010):
The German Reference Corpus DeReKo: A primordial sample for linguistic research. In: Calzolari, Nicoletta et al. (eds): Proceedings of the seventh conference on International Language Resources and Evaluation (LREC 2010). S. 1848-1854 - ELRA.
Kupietz, Marc/Witt, Andreas/Bański, Piotr/Tufiş, Dan/Cristea, Dan/Váradi, Tamás (2017):
EuReCo – Joining Forces for a European Reference Corpus as a sustainable base for cross-linguistic research. In: Bański, Piotr et al. (eds.): Proceedings of the Workshop on Challenges in the Management of Large Corpora and Big Data and Natural Language Processing (CMLC-5+BigNLP) 2017 including the papers from the Web-as-Corpus (WAC-XI) guest section. Birmingham, 24 July 2017. Mannheim: Institut für Deutsche Sprache, 2017. pp. 15-19.
Kupietz, Marc/Diewald, Nils/Trawiński, Beata/Cosma, Ruxandra/Cristea, Dan/Tufiş, Dan/Váradi, Tamás/Wöllstein, Angelika (2020):
Recent developments in the European Reference Corpus EuReCo. In: Granger, Sylviane/Lefer, Marie-Aude (Hrsg.): Translating and Comparing Languages: Corpus-based Insights. (= Corpora and Language in Use, Proceedings 6). Louvain-la-Neuve: Presses universitaires de Louvain, 2020. S. 257-273.
Kupietz, Marc/Diewald, Nils/Margaretha, Eliza (2020b):
RKorAPClient: An R Package for Accessing the German Reference Corpus DeReKo via KorAP. In: Calzolari, Nicoletta/Béchet, Frédéric/Blache, Philippe/Choukri, Khalid/Cieri, Christopher/Declerck, Thierry/Goggi, Sara/Isahara, Hitoshi/Maegaard, Bente/Mariani, Joseph/Mazo, Hélène/Moreno, Asuncion/Odijk, Jan/Piperidis, Stelios (Hrsg.): Proceedings of the 12th International Conference on Language Resources and Evaluation (LREC), May 11-16, 2020, Palais du Pharo, Marseille, France. Paris: European Language Resources Association, 2020. S. 7016-7021.
Kupietz, Marc/Diewald, Nils/Margaretha, Eliza (upcoming):
Building Paths to Corpus Data - A multi-level least effort and maximum return approach.
In: Fišer, Darja/Witt, Andreas (ed.): tba. DeGruyter.
Laviosa, Sara (1998). Core patterns of lexical use in a comparable corpus of
English narrative prose. Meta 43(4), 557-570.
McEnery, Anthony & Xiao, Richard (2007):
Parallel and comparable corpora: What are they up to? In G. James and G. Anderman (eds): Incorporating Corpora: Translation and The Linguist. Clevedon: Multilingual Matters. 18-32
Molnár, Valéria (2015):
The Predicationality Hypothesis. The Case of Hungarian and German. In É. Kiss, K., Surányi, B. & É. Dékány (eds). Approaches to Hungarian 14. Papers from the 2013 Piliscsaba Conference. Amsterdam: Benjamins, 209–244.
Rapp, Irene/Laptieva, Ekaterina/Koplenig, Alexander/Engelberg, Stefan (2017):
Lexikalisch-semantische Passung und argumentstrukturelle Trägheit – eine korpusbasierte Analyse zur Alternation zwischen dass-Sätzen und zu-Infinitiven in Objektfunktion. Deutsche Sprache 45(3). 193-221.
Taborek, Janusz (2020):
Kookkurrenz und syntagmatische Muster der Funktionsverbgefüge aus kontrastiver deutsch-polnischer Sicht am Beispiel in Not geraten.
[in:] De Knop, Sabine & Manon Hermann (Hrsg.), Funktionsverbgefüge im Fokus: Theoretische, didaktische und kontrastive Perspektiven, Berlin u.a.: de Gruyter, 211-233
Taborek, Janusz (2018):
Korpusbasiertes kontrastives Beschreibungsmodell für Funktionsverbgefüge.
In: Schmale, Günter (ed.): Lexematische und polylexematische Einheiten des Deutschen (Reihe Eurogermanistik), Tübingen: Stauffenburg, 135-154.
Taborek, Janusz (2018b):
Funktionsverbgefüge in bilingualen deutsch-polnischen Wörterbüchern. Korpusbasierte Analyse – syntagmatische Muster – Äquivalenz.
[in:] Jesenšek, V./Enčeva, M. (eds.), Wörterbuchstrukturen zwischen Theorie und Praxis. Herbert Ernst Wiegand zum 80. Geburtstag gewidmet. (= Lexikographica.Series Maior). Berlin: de Gruyter,197-214.
Teich, Elke (2003):
Cross-Linguistic Variation in System and Text: A Methodology for the Investigation of Translations and Comparable Texts. Berlin: Mouton de Gruyter.
Tufiș, Dan/Barbu Mititelu, Verginica/Irimia, Elena/Păiș, Vasile/Ion, Radu/Diewald, Nils/ Mitrofan, Maria/Onofrei, Mihaela (2019):
Little strokes fell great oaks. Creating CoRoLa, the reference corpus of contemporary Romanian. In: Cosma, Ruxandra/Kupietz, Marc (eds..), On design, creation and use of the Reference Corpus of Contemporary Romanian and its analysis tools. CoRoLa, KorAP, DRuKoLA and EuReCo, Revue Roumaine de Linguistique, 64(3). Bucharest: Editura Academiei Române.
van Noord, Gertjan/Bouma, Gosse/van Eynde, Frank/de Kok, Daniel/van der Linde, Jelmer/ Schuurman, Ineke/Sang, Erik Tjong Kim/Vandeghinste, Vincent. (2013):
Large Scale Syntactic Annotation of Written Dutch: Lassy. In Peter Spyns and Jan Odijk (eds.), Essential Speech and Language Technology for Dutch: the STEVIN Programme, 147–164, Springer.
Váradi, T. (2002):
The Hungarian National Corpus. In Rodríguez, M. & Araujo, C. (eds) Proceedings of LREC 2002, Las Palmas / Paris: ELRA, 385–389.
Vincze, Veronika & Csirik, Janos. (2010):
Hungarian Corpus of Light Verb Constructions. Proceedings of the 23rd International Conference on Computational Linguistics (Coling 2010): 1110-1118.
Appendix
Monolingual corpora
in linguistic research
-
source of evidence, also for quantitative studies, e. g.
-
Augustin (2017): contraction of prepositions and articles in German ( DeReKo ) and Italian (CORIS: Corpus di italiano scritto, PAISÀ corpus)
-
Taborek (2018, 2020): light verb constructions in German ( DeReKo ) and Polish (NKJP)
-
-
GDE-N: DeReKo , BNC, COCA, GloWBe, FRANTEXT, ABU, NKJP, HNC (Gunkel et al. 2017)
GDE-V: monolingual corpora for single case studies
Multilingual corpora
It has often been said that through corpora we can observe patterns in language that we did not know before (...) My contention is that this is especially true for multilingual corpora. We can see how languages differ, what they have in common, and - perhaps eventually - what characterizes language in general.
Johansson (2007)
Case Study:
(Non-)finite complementation and control
-
comparative study: German-Swedish-Dutch
-
Hartmann/Mucha/Trawiński/Wöllstein (in preparation)
-
Baseline: Wöllstein (2015), Brandt/Trawiński/Wöllstein (2016), Brand (2019).
-
-
Subject:
-
Structures with verbs segregating propositional / verbal finite and non-finite complements
-
-
Questioning:
-
Is there a correlation between preferences for (non)finite complementation and control ratios?
-
Case study: Background assumptions
-
Referential cohesion and event integration (Givón 1990:527).
-
The more the two events coded in the main and complement clauses share their referents, the more likely they are to be semantically integrated as a single event; and the less likely is the complement clause to be coded as an independent finite clause.
-
-
In relation to German (Rapp et al. 2017:197):
-
The more the embedding verb lexically tends to semantic control, the more often to-infinitives occur.
-
The less the embedding verb lexically tends to semantic control, the more frequently that-clauses occur.
-
Case study: The corpora
-
Corpora:
-
DeReKo / KoGra-DB (IDS Mannheim, Kupietz et al. 2010)
-
→ German
-
-
Språkbanken / Moderna (Gothenburg, Borin et al. 2012)
-
→ Swedish
-
-
LASSY Large (Groningen / Lueven, van Noord et al. 2013)
-
→ Dutch
-
-
Example: The monolingual corpora in the study
... on DE, SW, NL - Hartmann/Mucha/Trawiński/Wöllstein (forthcoming)
| Corpus | Word tokens | Sentence tokens | Text types (topic domains) | Pos-Tagging |
|---|---|---|---|---|
| DeReKo (subcorpus KoGra-DB) | 4.3 G | 200 M | 170 categories, e.g., newspaper, novel, poem, crime, fiction, doctoral dissertation, weather forecast, advertising brochure, horoscope, letter to the editor, guide etc. | TreeTagger (STTS), Conexor, Xerox |
| Språkbanken (subcorpus Moderna) | 13.3 G | 953 M | newspaper, magazine, proceeding, literature, Bloggmix, Twittermix, Wikipedia | SUC MSD-Tagset, UD |
| Lassy (subcorpus Large) | 0.8 G | 52 M | administrative, autocues, magazine, legal, (parliamentary) proceedings, web, Wikipedia, the annual speeches from the throne of of Queen Beatrix | CGN-Tagset, D-Coi/SoNaR |
-
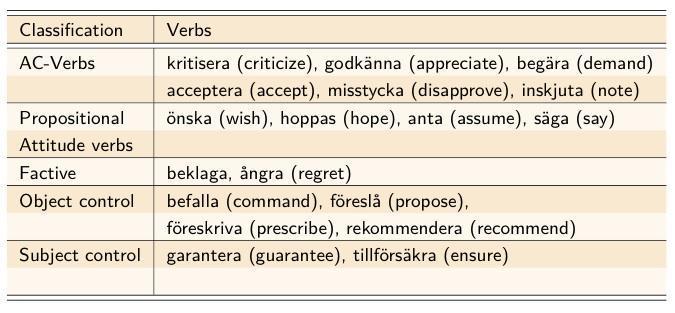
Object of study: distribution of different verb classes with different complement types:
-
with finite complements
-
with infinite complements with a complementizer
-
with infinite complements without a complementizer
-
Results for the German
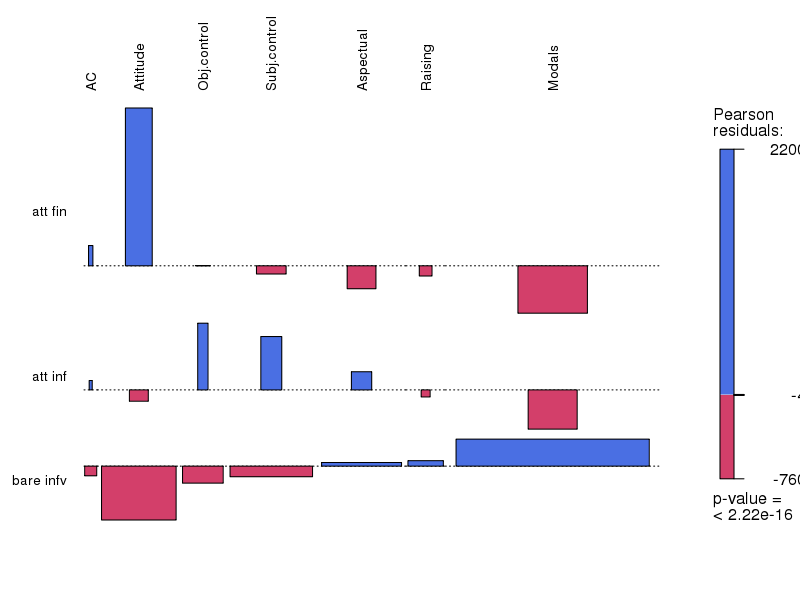
Verb categories 1: Swedish
Verb categories 2: Swedish
Verb categories 3: Swedish

Results for Swedish
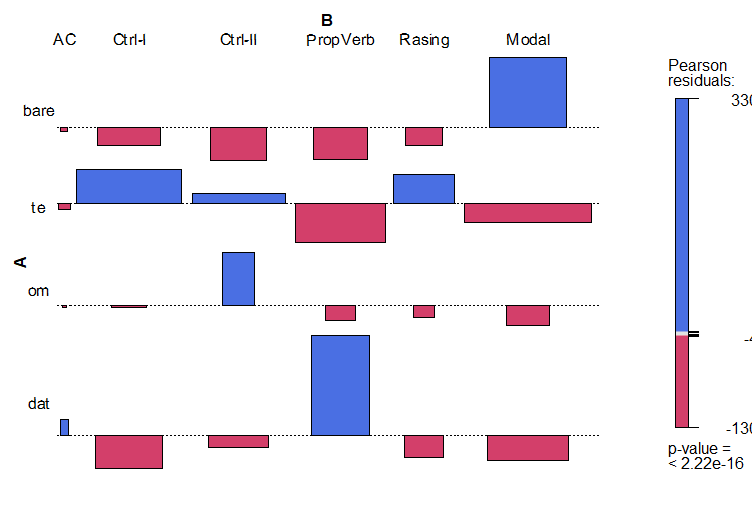
Results for Dutch
Summary and conclusion
-
The corpus studies show that there is a correlation between selection preferences and control ratios
-
the results confirm the hypothesis of referential cohesion and event integration
-
and show that it has cross-linguistic validity
-
-
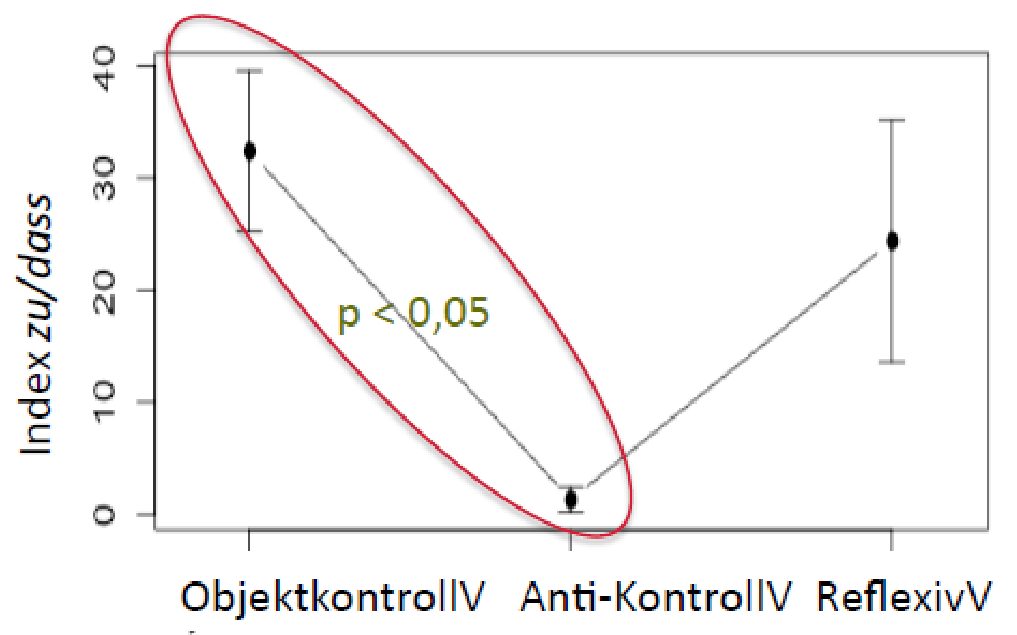
Methodological question: Are the results for German, Swedish and Dutch comparable?
-
The answer: yes and no
-
the results are comparable on a meta-level (level of generalizations)
-
at the empirical level (data level) they are less comparable
-
Example: The monolingual corpora in the study
... to the DE, SW, NL - Hartmann/Mucha/Trawiński/Wöllstein (forthcoming)
| Body | Word Token | Sentence token | Text types (different topics) | PoS tagging |
|---|---|---|---|---|
| DeReKo (Subcorpus KoGra-DB) | 4.3 G | 200 M | 170 categories: Press, novel, poem, mystery, fiction, dissertation, weather forecast, advertising brochure, horoscope, letter to the editor, travel guide, etc. | TreeTagger (STTS), Con- nexor, Xerox |
| Språkbanken (Subcorpus Moderna) | 13.3 G | 953 M | Press, Magazine, Minutes, Literature, Bloggmix, Twittermix, Wikipedia | SUC MSD tag set, UD |
| LASSY (Body Large) | 0.8 G | 52 M | 18 categories: Administrative texts, legal texts, journal, protocols (Europarl), web, Wikipedia, speeches from the throne of Queen Beatrix, etc. | CGN tagset, D-Coi/SoNaR |
Small parallel resources (selection)
Contrastive and typological studies
-
Bengt Altenberg (1999). Adverbial connectors in English and Swedish: Semantic and lexical correspondences. In Hasselgård & Oksefjell (eds.) Out of Corpora. Amsterdam: Rodopi, 249-268.
-
Hilde Hasselgård (2007). Using the ENPC and the ESPC as a parallel translation corpus: adverbs of frequency and usuality. Nordic Journal of English Studies 6:1.
-
Sandrine Zufferey & Bruno Cartoni (2012). English and French causal connectives in contrast. Languages in Contrast, Volume 12, Issue 2, 2012, pages 232 -250.
Typological studies
-
Johan van der Auwera & Ewa Schalley & Jan Nuyts (2005). Epistemic possibility in a Slavonic parallel corpus - a pilot study. In: P. Karlik & B. Hansen (eds.), Modality in Slavic languages. New Perspectives. Munich: Sagner, pages 201-217.
-
Federica da Milano (2007). Demonstratives in parallel texts: A case study. Linguistic Typology and Universal Research 60(2), pages 135-147.
-
Bernhard Wälchli (2007). Advantages and disadvantages of using parallel texts in typological investigations. Sprachtypologie und Universalienforschung 60(2), pages 118-134 (a case study of multi-verb constructions in the motion event domains BRING and RUN).
Discussions
-
Cysouw M., Wälchli B. (2007). Parallel texts: using translational equivalents in linguistic typology. STUF - Linguistic Typology and Universals Research 60(2), 95-99.
-
Granger, S.; Lerot, J.; Petch-Tyson, S. (eds.) (2003). Corpus-based Approaches to Contrastive Linguistics and Translation Studies. Amsterdam / Atlanta: Rodopi.
-
Granger, S. (2010). Comparable and translation corpora in cross-linguistic research. Design, analysis and applications. Journal of Shanghai Jiaotong University.
-
Johansson, S. (1999). Corpora and contrastive studies. In P. Pietilä & O-P. Salo (eds.) Multiple Languages - Multiple Perspectives. AFinLA Yearbook 1999 / No. 57, 116-125.
-
Johansson, S. (2007). Seeing through multilingual corpora. On the use of corpora in contrastive studies. Amsterdam: Benjamins.
Case study: Imperative
-
The underlying assumption: imperatives are used canonically in utterances expressing direct commands, requests, instructions, advice, etc.
-
require an agent: an entity capable of conscious and deliberate action
-
→ we can only ask someone to do something who has direct control over the action (Potsdam 1996, Jensen 2003).
-
-
Expected corpus distribution: imperative markers occur significantly more often with agentive verbs than with non-agentive verbs.
Case study: Imperative
-
Two goals:
-
test the agentivity hypothesis on the basis of corpus data
-
to test the cross-linguistic validity of the hypothesis
-
-
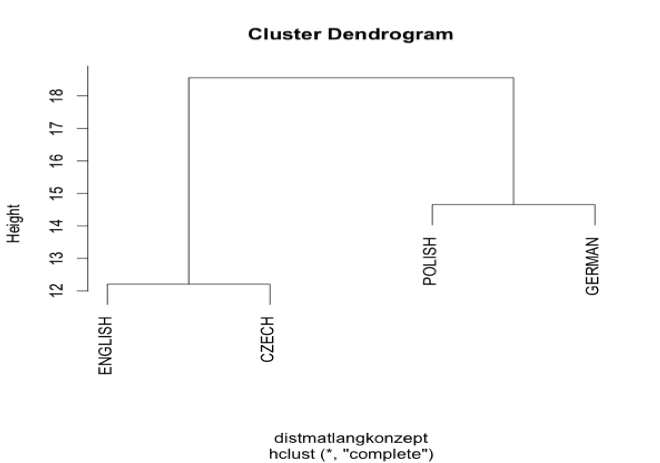
4 languages: English, German, Polish and Czech
-
Does the degree of relationship matter?
-
Data Source: InterCorp 6. Via KonText

Procedure
-
Extraction of imperative word forms with the help of CQP queries
-
Identification and selection of 50 most frequent lemmas (minimum frequency 10) from all lemmas underlying the imperative forms.
-
Mapping of all selected lemmas (language specific) to abstract event concepts based on FrameNet frame index (Baker et al., 1998).
The relevant concepts
-
MOTION (go / go, come / come etc.)
-
COMMUNICATION (say / say, listen / listen etc.)
-
GIVING/TAKING (give / give, take / take)
-
PERCEPTION (see / see, look / look etc.)
-
AWARENESS/COGITATION (understand / verstehen, think /denken etc.),
-
REMEMBERING (remember / remember, forget / forget etc.)
-
INTENTIONALLY-ACT (make / machen, do / tun etc.)
-
WAITING (wait / wait etc.)
-
BE (be / sein)
-
STOP/START (stop / stop, start / start etc.)
-
GETTING
-
INGESTION/COOKING (eat / eat, drink / drink etc.).
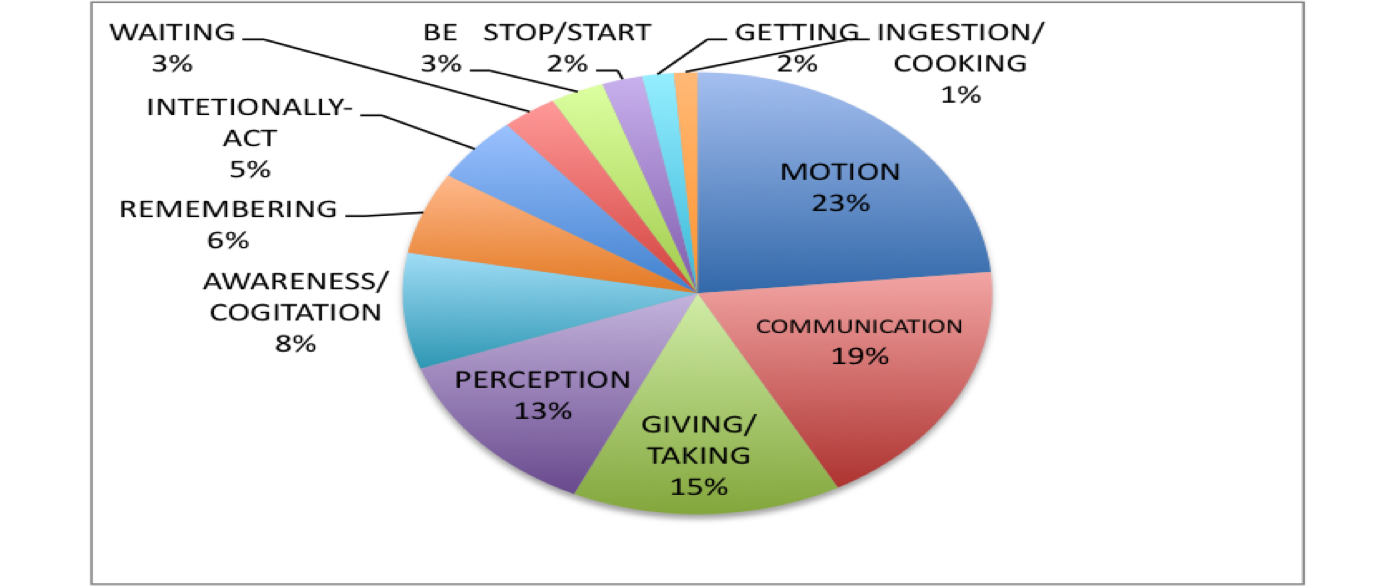
Distribution via concepts
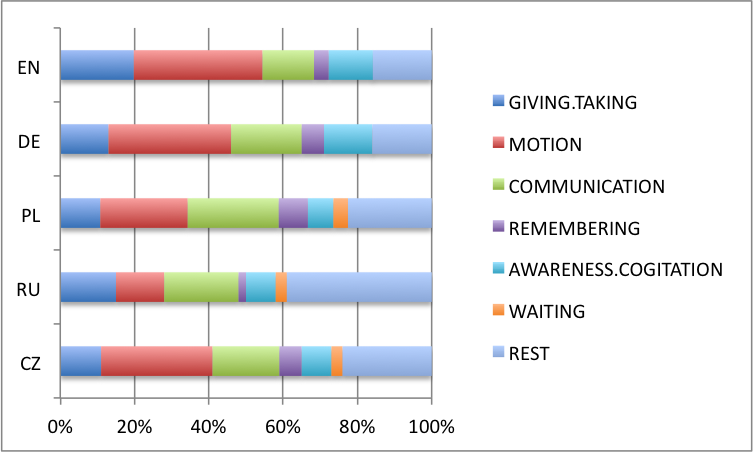
The overall distribution
-
The results confirm the hypothesis of agentivity:
-
Imperative markers are used significantly more often with agentive than with non-agentive verbs.
-
Language comparison
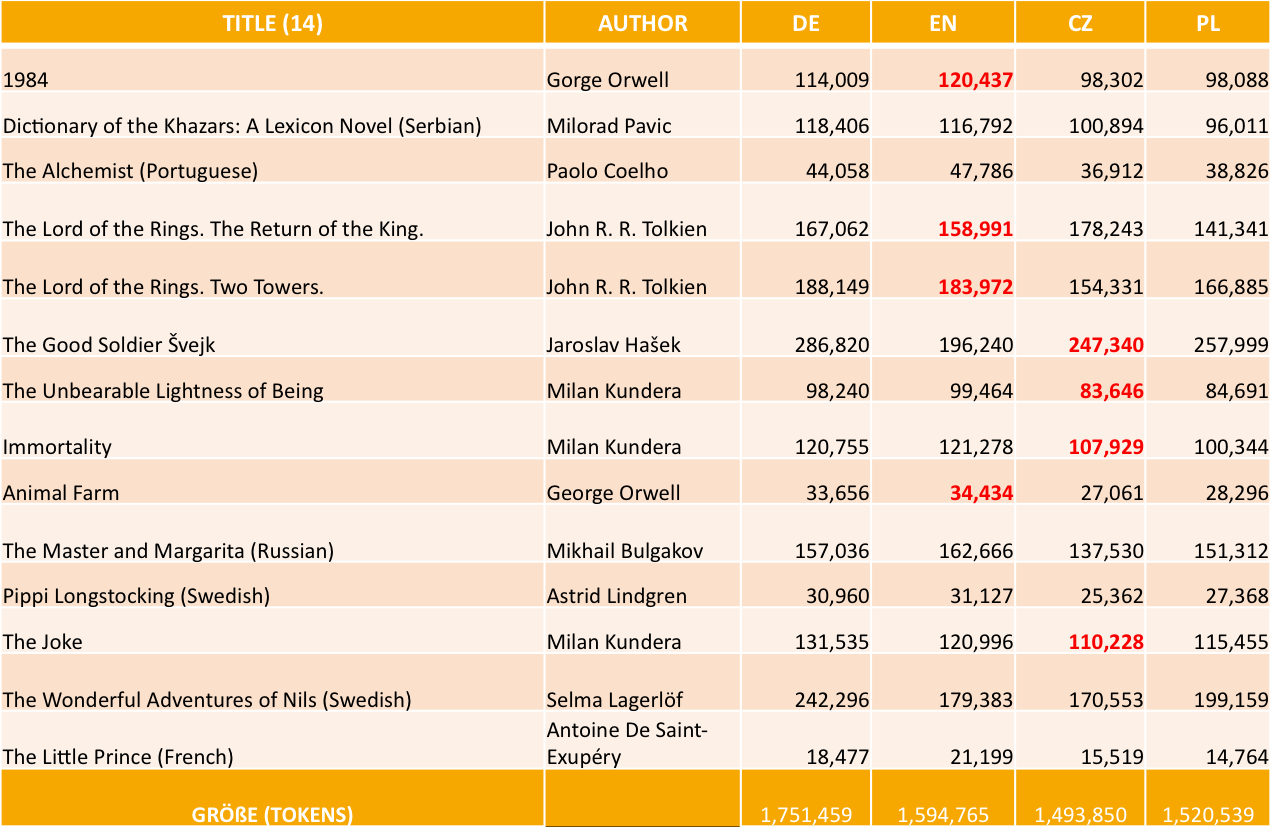
Example: The parallel data in the study
... to the imperative in DE, EN, PL, CZ - Trawiński (2016a, b)
Properties of translations: Laviosa (1998)
-
a relatively lower proportion of lexical units over functional units
-
a relatively higher proportion of high-frequency words over low-frequency words
-
a relatively greater repetition of the most frequent words
-
less variety in the words that are most frequently used
Properties of translations: Baker (1995)
-
simplification
-
translations tend to use simpler language
-
-
explicitation
-
translations show a tendency to spell things out
-
-
normalization
-
translations tend to conform to the typical patterns of the target language and to overuse its features
-
Properties of translations: Teich (2003)
-
shining-through (translations let the source language shine through)
-
normalisation (translations obey the target language norm more than comparable target language original texts)
-
Case studies for the German-English language pair: passive voice, transitivity, etc.
Case study: Passive (Teich 2003)
-
Passive is more typical in English than in German
-
Passive alternatives (man, sich lassen, -bar sein) are more typical in German than in English.
Case study: Passive (Teich 2003)
-
Hypotheses for E-ORI-G-TL
-
In translations from English into German, shining-through in the passive range is present if significantly more passives occur in G-TL than in comparable German texts (G-ORI).
-
In translations from English into German, normalization in the passive domain is present if significantly more passive alternatives occur in G-TL than in comparable German texts (G-ORI).
Case study: Passive (Teich 2003)
-
Hypotheses for G-ORI-E-TL
-
In translations from German into English, shining-through in the passive domain is present if significantly more passive alternatives occur in E-TL than in comparable English texts (E-ORI).
-
In translations from German into English, normalization in the passive range is present if significantly more passives occur in E-TL than in comparable English texts (E-ORI).
Case study: Passive (Teich 2003)
-
Weak shining-through in G-TL

-
No normalization effects in G-TL

Case study: Passive alternatives (Teich 2003)
-
no shining-through in E-TL

-
Normalization in E-TL

Possible requests
[drukola/m=pos:particle & drukola/m=type:negative] {,5} decît
Thematic composition of the corpus
according to CoRoLa taxonomy
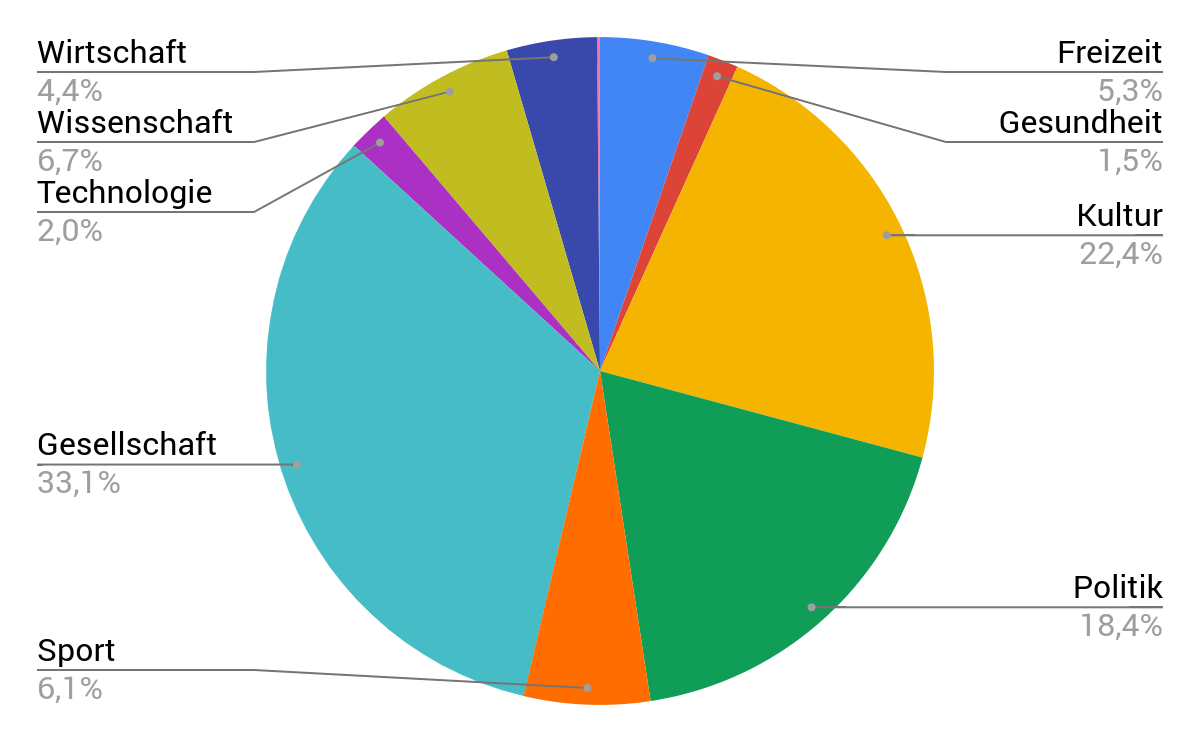
Flat quantitative characteristics
Flat quantitative features: Word Types
Graphics all generated with KorAP-R client package
library(RKorAPClient)
library(tidyverse)
library(highcharter)
library(kableExtra)
D <- new("KorAPConnection", verbose=T)
B <- D
DRuKoLAVC <- "referTo+drukola.20180909.1b_words"
baseVC = "corpusSigle=/U[0-9][0-9]/ | corpusSigle=/W.D17/"
R <- new("KorAPConnection", KorAPUrl = "http://89.38.230.10:5555/", verbose=T)
Dsize <- corpusStats(D, vc=DRuKoLAVC)@tokens
Rsize <- corpusStats(R)@tokens
Bsize <- corpusStats(D, vc=baseVC)@tokens
queryResultToHtml <- function(r) {
link <- slice(r, which.min(f))$webUIRequestUrl # use the query with less results
text_spec(round(r[1,]$f,2), color="blue", link=link, tooltip = r[1,]$query %>% str_replace_all('"', '"')) %>% str_replace(">", 'target="korap">')
}
add_comp <- function(.data, cat, n1, n2, b1) {
Design challenges
by "drukola-1b"
-
automatic and dynamic construction of the comparison corpus not yet possible with KorAP
-
Downsampling function is still missing
-
-
Text types classified differently and distributed very differently
-
Topic taxonomies each 2 levels but defined differently
-
DeReKo based on Open Directory Project (dmoz) (Weiß 2005, Klosa et al. 2012).
-
CoRoLa (Tufiş et al 2016) based on Universal Decimal Classification (UDC) and Wikipedia top-level domains (Gîfu et al 2019).
-
Construction of "DRuKoLA-1b"
-
Translation of the topic taxonomy of CoRoLA to that of DeReKo
-
e.g. Religion ➞ State/Society:Church, Art and Culture ➞ Culture, Medicine ➞ Health-Nutrition:Health
-
-
illustrations could be found for 89% of the CoRoLa texts
-
some categories incomplete, others inaccurately mapped
-
-
DeReKo large enough to fully mimic CoRoLa's theme distribution.
-
instead of sampling CoRoLa and DeReKo , only DeReKo was sampled.
Comparability?
-
whether corpora are sufficiently comparable cannot be decided in general, but depends, among other things, on the question to be answered
-
dynamically definable virtual comparable corpora, are a good approach to solve this problem.
-
especially since this can also adjust the composition as a whole
-
-
most important for now seems the practical comparability with the help of a uniform tool, mappable metadata and annotations
Levels of Access
Kupietz et al. (forthcoming)