Recent Developments in the European Reference Corpus EuReCo
UCCTS 2018, Louvain-la-Neuve, 2018-09-12
Overview
1. Introduction
Need for comparable corpora
-
parallel corpora alone are not suitable for finer-grained contrastive research
-
because of several translation effects:
-
simplification, explication, normalization (Backer 1995)
-
distributional biases (Laviosa 1998)
-
shining through effect (Teich 2003)
-
-
-
possible workaround: use a combination of parallel and monolingual corpora
-
however: complicated to handle for typical use cases
-
-
high-quality comparable corpora would be nice to have

No large, truly comparable corpora available
-
one exception:
-
Aranea – Family of Comparable Gigaword Web Corpora (Benko 2014)
-
however with uncontrolled comparability
-
-
in future – hopefully:
-
International Comparable Corpus (ICC) (Kirk & Čermáková 2017)
-
-
OTOH: there are many large national and reference corpora available:
-
ANC, BNC, CNC, CoRoLa, DeReKo , DWDS, HNC, NKJP, RNC, …
-
2. European Reference Corpus EuReCo
Idea of the EuReCo-initiative
-
use these existing national and reference corpora
-
and some software / infrastructure
-
to join sub-samples of them virtually and dynamically to (pairs of) comparable corpora
-
to ideally enable the user to, e. g.:
-
build the largest possible German-Hungarian comparable corpus with equal distribution of text types, topics and publication years starting from year 2000
-
to perform contrastive analysis on these virtual comparable corpora
-
Virtual joining is crucial
… because corpora are typically tied to their hosting institutions

Approach to achieve comparability
-
draw sub-samples of the existing corpora
-
based on metadata properties of individual texts:
-
topic domain
-
text type
-
publication date
-
…
-
-
so that the token distribution wrt. these metadata properties is similar in both sub-samples
-
-
challenge: in existing corpora these metadata properties are unlikely to be 1:1-mappable
Current state of EuReCo
Two (pilot) projects running
-
German-Romanian: DRuKoLA (2016-2018)
-
IDS, Bucharest University, Romanian Academy in Bucharest and Iaşi
-
state: first comparable corpora ready
-
-
German-Hungarian: DeutUng (2017-2019)
-
IDS, Szeged University, Hungarian Academy
-
state: first HNC sample available via KorAP
-
-
both projects funded by the Humboldt-Foundation
EuReCo’s software base: KorAP
-
corpus analysis platform developed mainly at the IDS as COSMAS-successor
-
beta running since 5/2017
-
still some important missing features:
-
most quantitative functions
-
sampling function for the creation of virtual corpora
(currently performed externally)
-
KorAP key features for EuReCo
-
KorAP can work with physically distributed data
-
all corpus data can stay where it is
-
-
allows dynamic definition of (comparable) sub-corpora
-
no relevant restrictions on data size and annotations
-
supports multiple query languages
-
has sustainable funding
-
is open source (BSD-licensed)
3. KorAP Demo
KorAP - Features for Comparable Corpora
DeReKo/CoRoLa
DeReKo/HNC - Contrastive Example
Molnár 2015
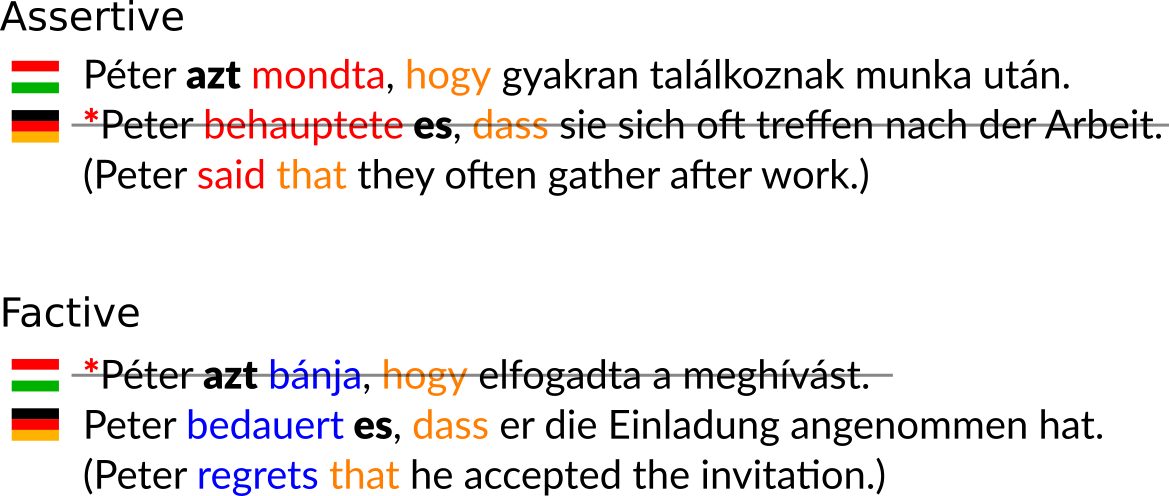
DeReKo/HNC - Demo
4. Summary and Future Plans
Summary
-
we need corpora for language comparison
-
big, overall goal:
-
-
not met by existing corpora
-
EuReCo & KorAP might provide a solution
-
by virtually joining existing national corpora
to comparable corpora
-
Next EuReCo steps
-
refine the current mappings by adding time and text type as additional comparability factors
-
integrate the HNC
-
explore differently defined comparable corpora
-
by their effect on quantitative distributions wrt case studies
-
-
implement missing KorAP features
-
draft an integrated UI for working with comparable corpora
-
ask more corpus providers to join
-
don't hesitate to contact us if you are interested
-
Thank you very much for your attention!
References
Axel-Tober, Katrin/Holler, Anke/Krause, Helena (2016):
Correlative es vs. das in German. An empirical perspective. In: Frey, Werner/Meinunger, André/Schwabe, Kerstin (Hg.) (2016): Inner-sentential propositional proforms. Syntactic properties and interpretative effects. Amsterdam/Philadelphia: Benjamins. (= Linguistik Aktuell 232),
Bański, Piotr/Bingel, Joachim/Diewald, Nils/Frick, Elena/Hanl, Michael/Kupietz, Marc/Pęzik, Piotr/Schnober, Carsten/Witt, Andreas (2013):
KorAP: the new corpus analysis platform at IDS Mannheim. In: Vetulani, Zygmunt/Uszkoreit, Hans (eds.): Human Language Technologies as a Challenge for Computer Science and Linguistics. Proceedings of the 6th Language and Technology Conference. S. 586-587 - Poznań: Fundacja Uniwersytetu im. A., 2013.
Bański, Piotr/Diewald, Nils/Hanl, Michael/Kupietz, Marc/Witt, Andreas (2014):
Access Control by Query Rewriting: the Case of KorAP. In: Proceedings of the 9th conference on the Language Resources and Evaluation Conference (LREC 2014), European Language Resources Association (ELRA), Reykjavic, Iceland, May 2014, pp. 3817—3822.
Benko, Vladimír (2014):
Aranea: Yet Another Family of (Comparable) Web Corpora. In Petr Sojka, Aleš Horák, Ivan Kopeček and Karel Pala (Eds.): Text, Speech and Dialogue. 17th International Conference, TSD 2014, Brno, Czech Republic, September 8-12, 2014. Proceedings. LNCS 8655. Springer International Publishing Switzerland, 2014. pp. 257-264. ISBN: 978-3-319-10815-5 (Print), 978-3-319-10816-2 (Online). BibTeX PDF
Cornilescu, Alexandra (2006):
Modes of Semantic Combination: NP/DP Adjectives. In Romance Languages and Linguistic Theory 2004 , J. Doetjes, P. Gonzalez (eds.), 43–71. Amsterdam: John Benjamins.
Cosma, Ruxandra/Cristea, Dan/Kupietz, Marc/Tufiş, Dan/Witt, Andreas (2016):
DRuKoLA – Towards Contrastive German-Romanian Research based on Comparable Corpora. In: Bański, Piotr/Barbaresi, Adrien/Biber, Hanno/Breiteneder, Evelyn/Clematide, Simon/Kupietz, Marc/Lüngen, Harald/Witt, Andreas: 4th Workshop on Challenges in the Management of Large Corpora. Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC 2016), Portorož, Slowenien. Paris: European Language Resources Association (ELRA), 2016. pp 28-32.
Cuba, Carlos de/Ürögdi, Barbara (2009):
Eliminating Factivity from Syntax. Sentential Complements in Hungarian. In: Den Dikken, Marcel/Vago, Robert Michael (Hg.): Approaches to Hungarian 11. Papers from the 2007 New York conference. Amsterdam/Philadelphia: Benjamins, 29–64.
Diewald, Nils/Margaretha, Eliza (2016):
Krill: KorAP search and analysis engine. In: Kupietz, Marc/Geyken, Alexander (Hrsg.): Corpus Linguistic Software Tools. Journal for language technology and computational linguistics (JLCL) 31 (1). (= Journal for Language Technology and Computational Linguistics 31.1). Berlin: GSCL, 2016. S. 73-90.
Granger, S./Lerot, J./Petch-Tyson, S. (Eds.) (2003):
Corpus-based Approaches to Contrastive Linguistics and Translation Studies. Amsterdam / Atlanta: Rodopi.
Granger, S. (2010):
Comparable and translation corpora in cross-linguistic research. Design, analysis and applications. Journal of Shanghai Jiaotong University.
Gray, Jim (2003):
Distributed Computing Economics. Technical Report MSR-TR-2003-24, Microsoft Research.
Greenbaum, Sidney (1991):
ICE: The international corpus of English. English Today, 7(4), 3-7.
James, Carl (1980):
Contrastive Analysis. London: Longman.
Johansson, S. (1999):
Corpora and contrastive studies. In P. Pietilä & O-P. Salo (Hrgs.) Multiple Languages – Multiple Perspectives. AFinLA Yearbook 1999 / No. 57, 116-125.
Johansson, Stig (2007):
Seeing through multilingual corpora. On the use of corpora in contrastive studies. Amsterdam: Benjamins.
Kirk, John, Anna Cermakova, Signe Oksefjell Ebeling, Jarle Ebeling, Michal Kren, Karin Aijmer, Vladimir Benko, Radovan Garabik, Rafal Gorski, Jarmo Jantunen, Marc Kupietz, Maria Simkova, Thomas Schmidt and Oliver Wicher (to appear in 2018):
Introducing the International Comparable Corpus. In Granger, S. & Lefer, M.-A. (eds.): Book of Abstracts of the Using Corpora in Contrastive and Translation Studies Conference (5th edition), Louvain-la-Neuve, 12-14 September 2018. CECL Papers 1, UCLouvain, Louvain-la-Neuve.
Kirk, John/Čermáková, Anna (2017):
From ICE to ICC: The new International Comparable Corpus. In Bański et al. (eds.): Proceedings of the Workshop on Challenges in the Management of Large Corpora and Big Data and Natural Language Processing (CMLC-5+BigNLP) 2017 including the papers from the Web-as-Corpus (WAC-XI) guest section
Koehn, Philipp (2005):
Europarl: A Parallel Corpus for Statistical Machine Translation. MT Summit 2005.
Kupietz, Marc/Belica, Cyril/Keibel, Holger/Witt, Andreas (2010):
The German Reference Corpus DeReKo: A primordial sample for linguistic research. In: Calzolari, Nicoletta et al. (eds): Proceedings of the seventh conference on International Language Resources and Evaluation (LREC 2010). S. 1848-1854 - ELRA.
Kupietz, Marc/Witt, Andreas/Bański, Piotr/Tufiş, Dan/Cristea, Dan/Váradi, Tamás (2017):
EuReCo – Joining Forces for a European Reference Corpus as a sustainable base for cross-linguistic research. In: Bański, Piotr et al. (eds.): Proceedings of the Workshop on Challenges in the Management of Large Corpora and Big Data and Natural Language Processing (CMLC-5+BigNLP) 2017 including the papers from the Web-as-Corpus (WAC-XI) guest section. Birmingham, 24 July 2017. Mannheim: Institut für Deutsche Sprache, 2017. pp. 15-19.
Kupietz, Marc/Cosma, Ruxandra/Cristea, Dan/Diewald, Nils/Trawiński, Beata/Tufiş, Dan/Váradi, Tamás/Wöllstein, Angelika (to appear in 2018):
Recent Developments in the European Reference Corpus EuReCo. In Granger, S. & Lefer, M.-A. (eds.): Book of Abstracts of the Using Corpora in Contrastive and Translation Studies Conference (5th edition), Louvain-la-Neuve, 12-14 September 2018. CECL Papers 1, UCLouvain, Louvain-la-Neuve.
Molnár, Valéria (2015):
The Predicationality Hypothesis. The Case of Hungarian and German. In: É. Kiss, Katalin/Surányi, Balázs/Dékány, Éva (Hg.): Approaches to Hungarian 14. Papers from the 2013 Piliscsaba Conference. Amsterdam: Benjamins, 209–244.
Sudhoff, Stefan (2003):
Argumentsätze und es-Korrelate. Zur syntaktischen Struktur von Nebensatzeinbettungen im Deutschen. Berlin: Wissenschaftlicher Verlag Berlin.
Sudhoff, Stefan (2016):
Argumentsätze und es-Korrelate – zur syntaktischen Struktur von Nebensatzeinbettungen im Deutschen. In: Frey, Werner/Meinunger, André/Schwabe, Kerstin (Hg.) (2016): Inner-sentential propositional proforms. Syntactic properties and interpretative effects.
Teich, Elke (2003):
Cross-Linguistic Variation in System and Text: A Methodology for the Investigation of Translations and Comparable Texts. Berlin: Mouton de Gruyter.
Tufiş, D., Barbu Mititelu, V., Irimia, E., Dumitrescu, Ș. D. and Boroş, T. (2016):
The IPR-cleared Corpus of Contemporary Written and Spoken Romanian Language. In: Calzolari, N. et al. (eds.): Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC'16), Portoroz / Paris: ELRA.
van Noord, Gertjan/Bouma, Gosse/van Eynde, Frank/de Kok, Daniel/van der Linde, Jelmer/ Schuurman, Ineke/Sang, Erik Tjong Kim/Vandeghinste, Vincent. (2013):
Large Scale Syntactic Annotation of Written Dutch: Lassy. In Peter Spyns and Jan Odijk (eds.), Essential Speech and Language Technology for Dutch: the STEVIN Programme, 147–164, Springer.
Appendix
Multilingual corpora
It has often been said that, through corpora, we can observe patterns in language which we were unaware of before (…) My claim is that this applies particularly to multilingual corpora. We can see how languages differ, what they share and – perhaps eventually – what characterises language in general.
Johansson (2007)
Comparable corpus
Definition
-
a comparable corpus consists of two or more monolingual corpora that have similar compositions wrt relevant properties (time, genre, topic domain, …)
-
(ideally) contains original texts only
-
-
early prominent example:
-
International Corpus of English (ICE) (Greenbaum 1991)
-
contains twelve corpora of different national or regional varieties of English with a controlled, similar composition
-
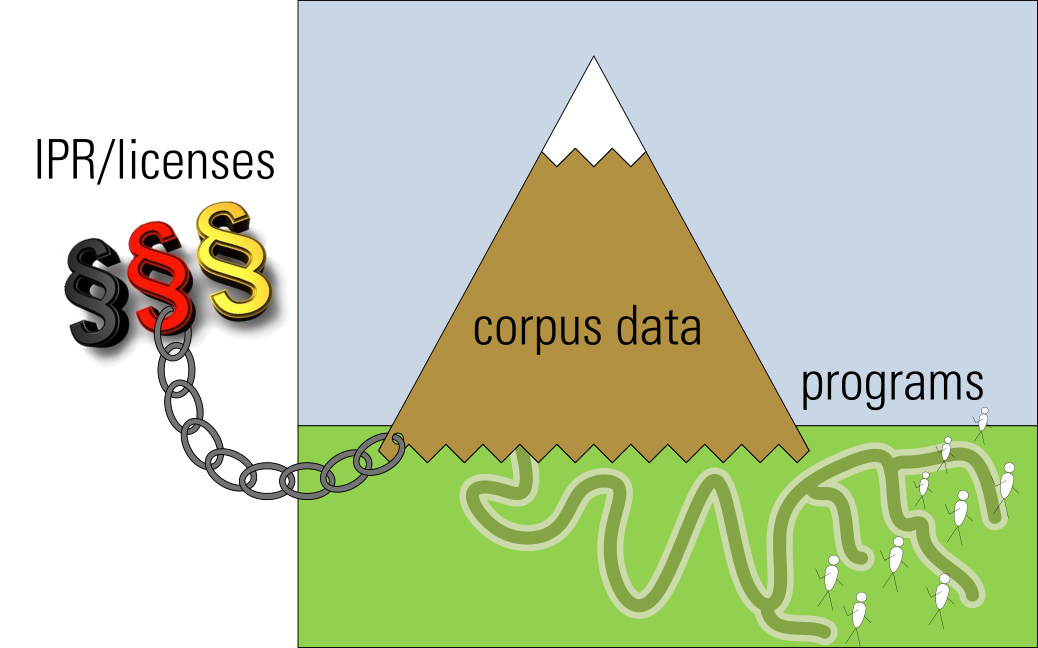
Problem: IPR and license contracts
… typically tie existing corpora to their hosting institutions
If the data cannot move …

…find ways to put the computation near the data
Jim Gray (2003)
Translated to EuReCo
… build some infrastructure to use the data from where it is.
How to achieve “comparability”?
Basic approach: (Cosma et al. 2016)
-
draw comparable sub-samples of the existing corpora
-
using KorAP's virtual collection feature
-
-
based on metadata properties of individual texts:
-
topic domain
-
text type
-
publication date
-
…
-
-
comparable ≙ equal token distribution wrt. these metadata properties
Apply this approach iteratively
to gradually approximate good/sufficient comparability
-
start with a good mapping of metadata properties
-
define a preliminary comparable corpus pair
-
perform comparative case studies
-
refine mapping, if findings seem to be artifacts of comparability criteria and start over with 2
-
side-question: how stable are the quantitative effects over different comparable corpora
-
-

Mapping of CoRoLa topic domains to DeReKo
In order to construct a first comparable corpus
| CoRoLa (based on Wikipedia) | DeReKo (based on Open Directory) | Texts |
|---|---|---|
| Society | Staat_Gesellschaft | 53221 |
| Art And Culture | Kultur | 16792 |
| Science | Wissenschaft | 2343 |
| Music | Kultur:Musik | 6352 |
| Literature | Kultur:Literatur | 1073 |
| Education | Staat_Gesellschaft:Bildung | 405 |
| History | 230 | |
| Medicine | Gesundheit_Ernaehrung:Gesundheit | 183 |
| Economy | Wirtschaft_Finanzen | 143 |
| Pedagogy | Staat_Gesellschaft:Familie_Geschlecht | 124 |
| Health | Gesundheit_Ernaehrung:Gesundheit | 113 |
| Sociology | Staat_Gesellschaft | 110 |
| Religion | Staat_Gesellschaft:Kirche | 108 |
| Philosophy | 100 | |
| Psychology | 82 | |
| Sport | Sport | 78 |
| Philology | 75 | |
| Linguistics | 69 | |
| Politics | Politik | 68 |
| Religious Studies and Theology | Staat_Gesellschaft:Kirche | 51 |
| Administration | Politik:Inland | 42 |
| Political Sciences | Politik | 42 |
| Chemistry | 37 | |
| Geography | 32 | |
| Folklore | 32 | |
| Anthropology | 30 | |
| Poetry | Kultur:Literatur | 24 |
| Entertainment | Freizeit_Unterhaltung | 21 |
| Biology | 21 | |
| Social Events | 18 | |
| Painting and Drawing | Kultur:Bildende_Kunst | 15 |
| Theatre | Kultur:Darstellende_Kunst | 14 |
| Physics | Wissenschaft | 14 |
| Environment | Natur_Umwelt | 12 |
Risks & Challenges 1: Comparability
-
text property taxonomies are not easily 1:1-mappable between different corpora
-
text type / genre: pretty hopeless
-
topic domain
-
several internationally established taxonomies: e.g. UDC, Open Directory, Wikipedia Categories
-
but none of them alone seems ideal for corpora
-
Risks & Challenges 2:
Composition & Coverage
-
comparable corpus composition and coverage depend on the composition of the respective underlying monolingual corpora:
-
each comparable stratum is limited to the size of the lesser populated one in the monolingual sources
-
-
because of the decentral structure of EuReCo missing/underpopulated strata cannot be added easily
-
e.g. Wikipedia Talk Pages in CoRoLa
-
Risks & Challenges 3:
Reliance on a single software
-
KorAP is open source and so are the APIs
-
it's sometimes easier to deploy an additional corpus query tool in many places than to develop and maintain an equivalent API for many corpus tools (my lessons learned from CLARIN)
-
solution: don't replace your existing query tool with KorAP, but run KorAP in addition
-
also at the IDS, KorAP is currently only a secondary query tool
-
Arbitrary number of annotation layers
Romanian: Adjective serialization
Assertive verbs with or without correlate
CoRoLa live
DRuKoLa/CoRoLa Comparation