Von monolingualen Korpora über Parallel- und Vergleichskorpora zum Europäischen Referenzkorpus EuReCo
IDS-Jahrestagung, Mannheim, 2020-03-11
Ziele des Vortrags sind …
-
die Anforderungen an Sprachkorpora für den Sprachvergleich zu diskutieren
-
auf Problematiken der vorhandenen Lösungen hinzuweisen
-
neue Perspektiven zu skizzieren, die die EuReCo -Initiative für germanistische und vergleichende Korpuslinguistik eröffnet, insbesondere im europäischen Kontext
Hintergrund
-
große Bedeutung von Korpora für die linguistische Forschung, sowohl im einzelsprachlichen als auch sprachübergreifenden Kontext
-
die Anzahl der linguistischen Studien, die auf Korpusdaten basieren, steigt
-
die Anzahl (und die Größe) von Korpora wächst
-
der Linguist steht oft vor der Wahl zwischen mehreren unterschiedlichen Korpustypen
-
verschiedene Optionen für die sprachübergreifende Forschung →
Korpora für den Sprachvergleich
Korpora für den Sprachvergleich
1. Einsprachige Korpora
Einsprachige Korpora
-
Texte in nur einer Sprache
-
in der Regel originalsprachig, daher von hoher Qualität
-
seit den 1960er-Jahren ( DeReKo seit 1964)
-
Beispiele für große nationale Referenzkorpora:
-
ANC, BNC, CNC, CoRoLa, DeReKo , HNC, NKJP, RNC, ...
-
-
in der Regel linguistisch annotiert
Einsprachige Korpora
in sprachvergleichender Forschung
-
als Belegquelle, auch für quantitative Untersuchungen, z. B.
-
Augustin (2017): Verschmelzung von Präposition und Artikel im Deutschen ( DeReKo ) und Italienischen (CORIS: Corpus di italiano scritto, PAISÀ-Korpus)
-
Taborek (2018): Funktionsverbgefüge im Deutschen ( DeReKo ) und Polnischen (NKJP)
-
-
GDE-N: DeReKo , BNC, COCA, GloWBe, FRANTEXT, ABU, NKJP, HNC (Gunkel et al. 2017)
-
GDE-V: einsprachige Korpora für einzelne Fallstudien
Fallstudie:
(Nicht-)finite Komplementierung und Kontrolle
-
vergleichende Studie: Deutsch-Schwedisch-Niederländisch
-
Hartmann/Mucha/Trawiński/Wöllstein (in Vorbereitung)
-
Ausgangsbasis: Wöllstein (2015), Brandt/Trawiński/Wöllstein (2016), Brand (2019)
-
-
Gegenstand:
-
Strukturen mit Verben, die propositionale / verbhaltige finite und nicht-finite Komplemente selegieren
-
-
Fragestellung:
-
Gibt es eine Korrelation zwischen Präferenzen für (nicht-)finite Komplementierung und Kontrollverhältnissen?
-
Fallstudie: Hintergrundannahmen
-
Referentielle Kohäsion und Ereignisintegration (Givón 1990:527)
-
The more the two events coded in the main and complement clauses share their referents, the more likely they are to be semantically integrated as a single event; and the less likely is the complement clause to be coded as an independent finite clause.
-
-
In Bezug auf das Deutsche (Rapp et al. 2017:197):
-
Je mehr das einbettende Verb lexikalisch zu semantischer Kontrolle tendiert, desto häufiger treten zu-Infinitive auf.
-
Je weniger das einbettende Verb lexikalisch zu semantischer Kontrolle tendiert, desto häufiger treten dass-Sätze auf.
-
Fallstudie: Die Korpora
-
Korpora:
-
DeReKo / KoGra-DB (IDS Mannheim, Kupietz et al. 2010)
-
→ Deutsch
-
-
Språkbanken / Moderna (Göteborg, Borin et al. 2012)
-
→ Schwedisch
-
-
LASSY Large (Groningen / Lueven, van Noord et al. 2013)
-
→ Niederländisch
-
-
-
Untersuchungsgegenstand: Distribution von verschiedenen Verbklassen mit verschiedenen Komplementtypen:
-
mit finiten Komplementen
-
mit infiniten Komplementen mit einem Komplementierer
-
mit infiniten Komplementen ohne einen Komplementierer
-
Ergebnisse für das Deutsche
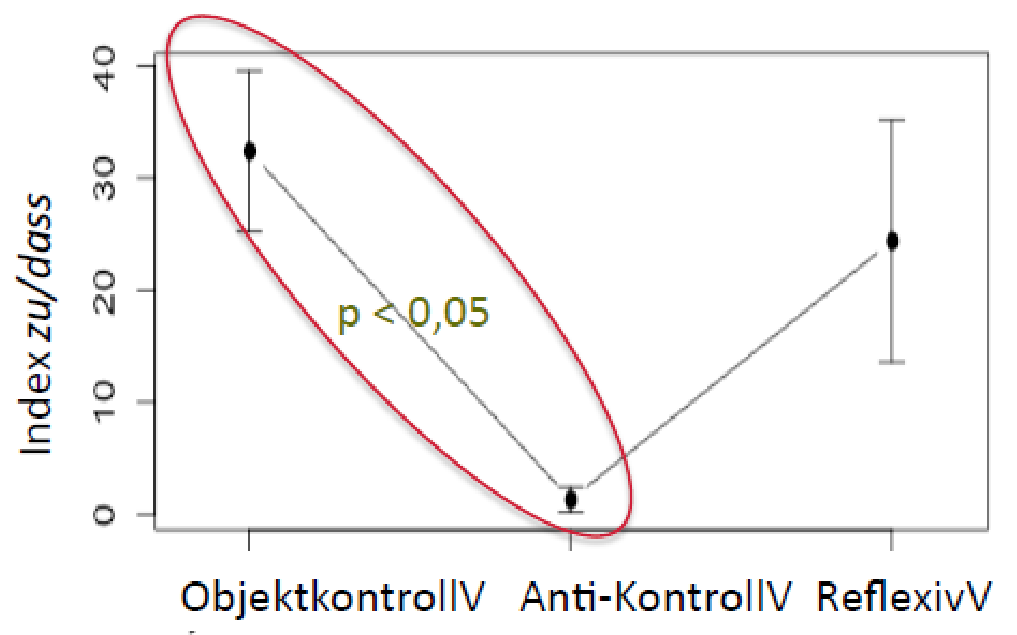
Ergebnisse für das Schwedische
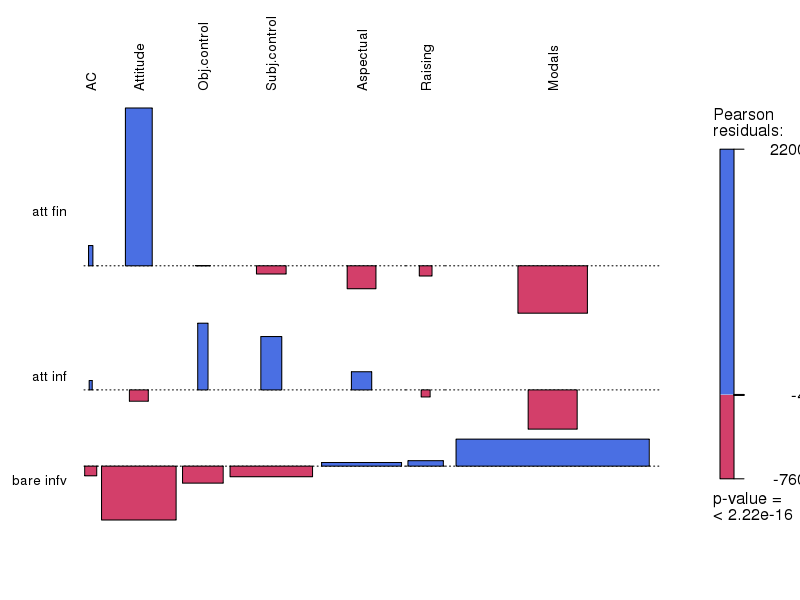
Ergebnisse für das Niederländische
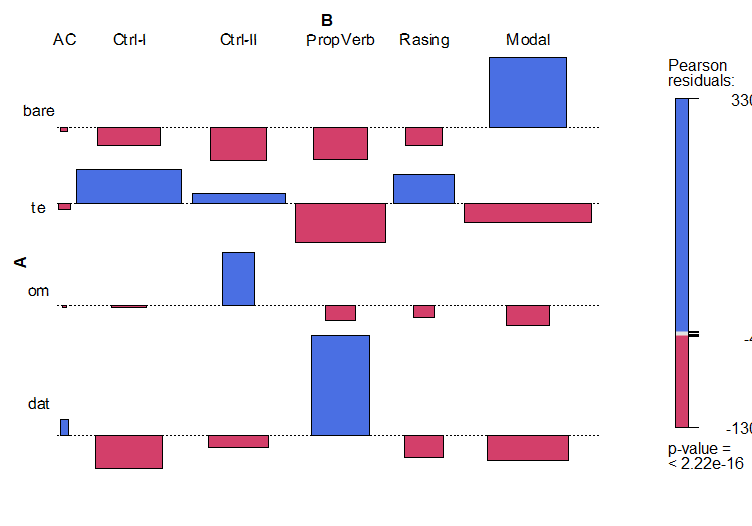
Zusammenfassung und Fazit
-
Die Korpusuntersuchungen zeigen, dass es eine Korrelation zwischen Selektionspräferenzen und Kontrollverhältnissen gibt
-
die Ergebnisse bestätigen die Hypothese der referentiellen Kohäsion und Ereignisintegration
-
und zeigen, dass diese eine sprachübergreifende Gültigkeit hat
-
-
Methodische Frage: Sind die Ergebnisse für das Deutsche, das Schwedische und das Niederländische vergleichbar?
-
Die Antwort: ja und nein
-
die Ergebnisse sind auf einer Metaebene (Ebene der Generalisierungen) vergleichbar
-
auf der empirischen Ebene (Datenebene) sind sie weniger vergleichbar
-
Die zugrunde liegenden einsprachigen Korpora
| Korpus | Worttoken | Satztoken | Texttypen (verschiedene Themenbereiche) |
|---|---|---|---|
| DeReKo (Sublkorpus KoGra-DB) | 4.3 G | 200 M | 170 Kategorien: Presse, Roman, Gedicht, Krimi, Belletristik, Dissertation, Wettervorhersage, Werbebroschüre, Horoskop, Leserbrief, Reiseführer etc. |
| Språkbanken (Sublkorpus Moderna) | 13.3 G | 953 M | Presse, Zeitschrift, Protokolle, Literatur, Bloggmix, Twittermix, Wikipedia |
| LASSY (Korpus Large) | 0.8 G | 52 M | 18 Kategorien: Verwaltungstexte, juristische Texte, Zeitschrift, Protokolle (Europarl), Web, Wikipedia, Thronreden der Königin Beatrix etc. |
Zusammenfassung: Einsprachige Korpora
-
geringe Übereinstimmung bezüglich der Größe, Texttypen, Themen etc.
-

-
jedoch hohe sprachliche Qualität
-

2. Parallele Korpora
Parallele Korpora
-
Parallelkorpora bestehen aus Originaltexten in einer Sprache (Quellsprache) und ihren Übersetzungen in anderen Sprachen (Zielsprachen)
-
Texte in allen Sprachen auf Satzebene aligniert
-
teilweise linguistisch annotiert
-
seit den 1990er-Jahren
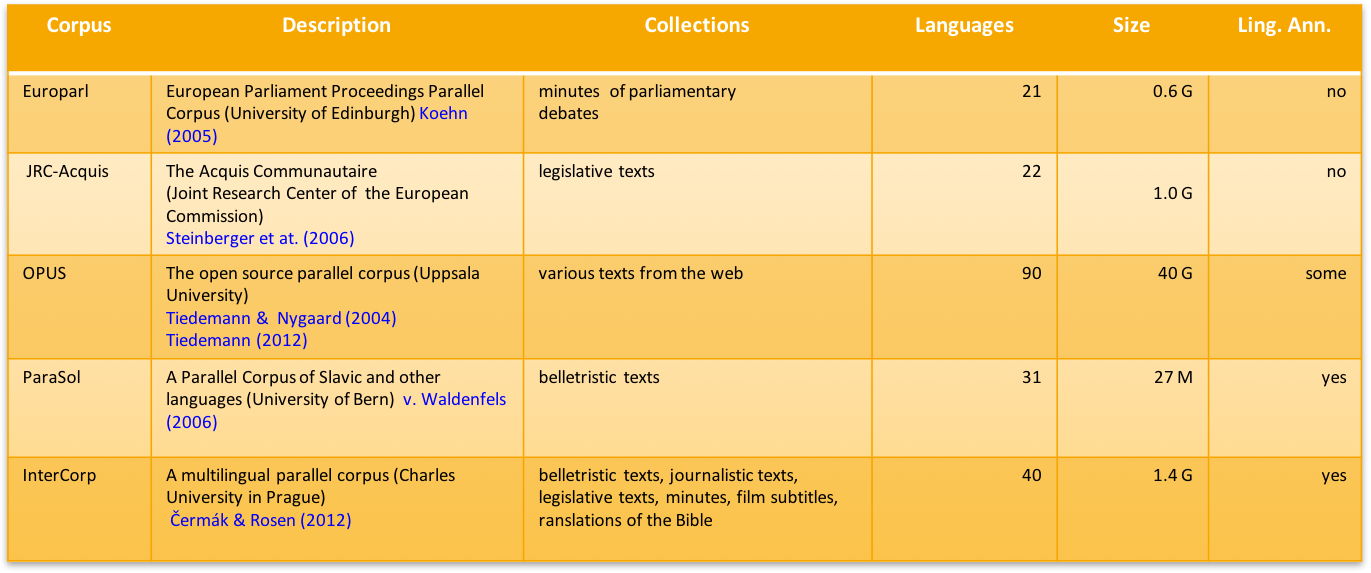
Große mehrsprachige Parallelkorpora
Kleine parallele Ressourcen (Auswahl)

Vorteile von Parallelkorpora
-
Paralleldaten: Sequenzen von sprachlichen Einheiten (Wörter, Sätze) in zwei oder mehreren Sprachen,
-
die Übersetzungsäquivalente voneinander sind und als solche die gleiche Bedeutung transportieren
-
in den gleichen Kontexten verwendet werden
-
in den gleichen Texttypen aus den gleichen Zeiträumen etc. vorkommen
-
-
perfekte Grundlage für die Ermittlung der funktionalen Äquivalenz zwischen sprachlichen Strukturen (James 1980, Chesterman 1998) → tertium comparationis
-
Einblicke in sprachübergreifende Ähnlichkeiten und Unterschiede, die bei der Arbeit mit einsprachigen Korpora übersehen werden könnten
Kontrastive Studien
-
Bengt Altenberg (1999). Adverbial connectors in English and Swedish: Semantic and lexical correspondences. In Hasselgård & Oksefjell (eds.) Out of Corpora. Amsterdam: Rodopi, 249-268.
-
Hilde Hasselgård (2007). Using the ENPC and the ESPC as a parallel translation corpus: adverbs of frequency and usuality. Nordic Journal of English Studies 6:1.
-
Sandrine Zufferey & Bruno Cartoni (2012). English and French causal connectives in contrast. Languages in Contrast, Volume 12, Issue 2, 2012, pages 232 –250.
Typologische Studien
-
Johan van der Auwera & Ewa Schalley & Jan Nuyts (2005). Epistemic possibility in a Slavonic parallel corpus – a pilot study. In: P. Karlik & B. Hansen (eds.), Modalität in slavischen Sprachen. Neue Perspektiven. München: Sagner, pages 201–217.
-
Federica da Milano (2007). Demonstratives in parallel texts: A case study. Sprachtypologie und Universalienforschung 60(2), pages 135–147.
-
Bernhard Wälchli (2007). Advantages and disadvantages of using parallel texts in typological investigations. Sprachtypologie und Universalienforschung 60(2), pages 118–134. (a case study of multi-verb constructions in the motion event domains BRING and RUN)
Diskussionen
-
Cysouw M., Wälchli B. (2007). Parallel texts: using translational equivalents in linguistic typology. STUF - Sprachtypologie und Universalienforschung 60(2), 95–99.
-
Granger, S.; Lerot, J.; Petch-Tyson, S. (Hrsg.) (2003). Corpus-based Approaches to Contrastive Linguistics and Translation Studies. Amsterdam / Atlanta: Rodopi.
-
Granger, S. (2010). Comparable and translation corpora in cross-linguistic research. Design, analysis and applications. Journal of Shanghai Jiaotong University.
-
Johansson, S. (1999). Corpora and contrastive studies. In P. Pietilä & O-P. Salo (Hrgs.) Multiple Languages – Multiple Perspectives. AFinLA Yearbook 1999 / No. 57, 116-125.
-
Johansson, S. (2007). Seeing through multilingual corpora. On the use of corpora in contrastive studies. Amsterdam: Benjamins.
Fallbeispiel: Imperativ
-
Die zugrunde liegende Annahme: Imperative werden kanonisch in Äußerungen verwendet, die direkte Befehle, Bitten, Anweisungen, Ratschläge usw. ausdrücken.
-
erfordern ein Agens: eine Entität, die zum bewussten und vorsätzlichen Handeln fähig ist
-
→ wir können nur jemanden auffordern, etwas zu tun, der über das Handeln eine direkte Kontrolle hat (Potsdam 1996, Jensen 2003)
-
-
Erwartete Korpusdistribution: Imperativ-Markierungen kommen bei agentivischen Verben signifikant häufiger vor als bei nicht-agentivischen Verben
Fallbeispiel: Imperativ
-
Zwei Ziele:
-
die Agentivitätshypothese auf der Basis von Korpusdaten zu überprüfen
-
die sprachübergreifende Gültigkeit der Hypothese zu überprüfen
-
-
4 Sprachen: Englisch, Deutsch, Polnisch und Tschechisch
-
Spielt der Verwandschaftsgrad eine Rolle?
-
Datenquelle: InterCorp 6. über KonText

Vorgehen
-
Extraktion von imperativischen Wortformen mit Hilfe von CQP-Abfragen
-
Identifizierung und Auswahl von 50 häufigsten Lemmata (Minimalfrequenz 10) aus allen den Imperativformen zugrunde liegenden Lemmata
-
Abbildung aller ausgewählten Lemmata (sprachspezifisch) auf abstrakte Ereigniskonzepte, die auf FrameNet-Frame-Index basieren (Baker et al., 1998)
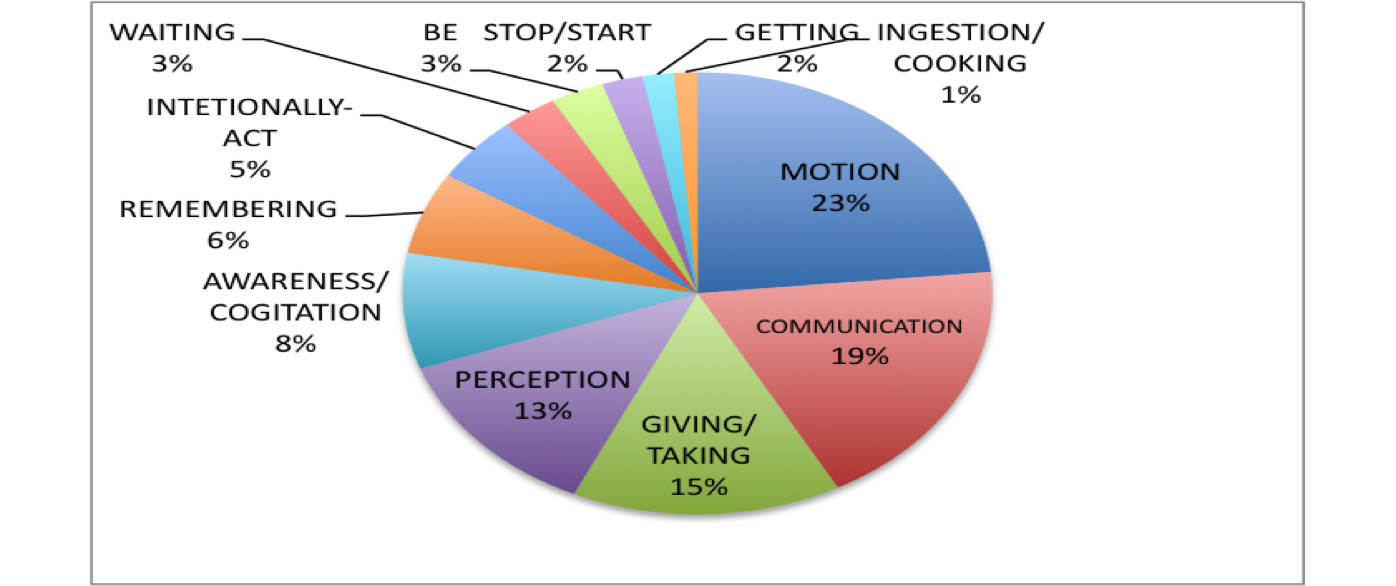
Die relevanten Konzepte
-
MOTION (go / gehen, come / kommen etc.)
-
COMMUNICATION (say / sagen, listen / hören etc.)
-
GIVING/TAKING (give / geben, take / nehmen)
-
PERCEPTION (see / sehen, look / schauen etc.)
-
AWARENESS/COGITATION (understand / verstehen, think /denken etc.),
-
REMEMBERING (remember / erinnern, forget / vergessen etc.)
-
INTENTIONALLY-ACT (make / machen, do / tun etc.)
-
WAITING (wait / warten etc.)
-
BE (be / sein)
-
STOP/START (stop / aufhören, start / beginnen etc.)
-
GETTING (get / kriegen)
-
INGESTION/COOKING (eat / essen, drink / trinken etc.).
Die Gesamtverteilung
-
Die Ergebnisse bestätigen die Hypothese der Agentivität:
-
Imperativ-Markierungen werden deutlich häufiger bei agentivischen als bei nicht-agentivischen Verben verwendet.
-
Sprachvergleich
Die zugrunde liegenden Paralleldaten
Probleme mit Parallelkorpora
-
relativ geringe Größe
-
je mehr Sprachen, desto kleiner und weniger differenziert ist das Korpus
-
-
unausgewogen in Bezug auf Originaltexte und Übersetzungen
-
spezifische Eigenschaften von Übersetzungen (ein dritter Code)
Merkmale von Übersetzungen: Laviosa (1998)
-
relativ geringer Anteil von lexikalischen Wörter gegenüber Funktionswörtern
-
relativ hoher Anteil von hochfrequenten Wörtern gegenüber niedrigfrequenten Wörtern
-
häufige Wiederholung von häufigsten Wörtern
-
niedrige Varietät bei häufigsten Wörtern
Merkmale von Übersetzungen: Backer (1995)
-
Vereinfachung
-
Übersetzungen neigen dazu, eine einfachere Sprache zu verwenden
-
-
Verdeutlichung
-
Übersetzungen zeigen die Tendenz, Dinge zu verdeutlichen
-
-
Normalisierung
-
Übersetzungen neigen dazu, typische Mustern der Zielsprache zu verfolgen und diese dadurch übermäßig zu gebrauchen
-
Merkmale von Übersetzungen: Teich (2003)
-
shining-through
-
Normalisierung
Fallbeispiel: Passiv (Teich 2003)
-
Passiv ist im Englischen typischer als im Deutschen
-
Passivalternativen (man, sich lassen, -bar sein) sind im Deutschen typischer als im Englischen
Fallbeispiel: Passiv (Teich 2003)
-
Hypothesen für E-ORI-G-TL
-
In Übersetzungen vom Englischen ins Deutsche liegt shining-through im Passivbereich vor, wenn in G-TL signifikant mehr Passive auftreten als in vergleichbaren deutschen Texten (G-ORI)
-
In Übersetzungen vom Englischen ins Deutsche liegt Normalisierung im Passivbereich vor, wenn in G-TL signifikant mehr Passivalternativen auftreten als in vergleichbaren deutschen Texten (G-ORI)
Fallbeispiel: Passiv (Teich 2003)
-
Hypothesen für G-ORI-E-TL
-
In Übersetzungen vom Deutschen ins Englische liegt shining-through im Passivbereich vor, wenn in E-TL signifikant mehr Passivalternativen auftreten als in vergleichbaren englischen Texten (E-ORI)
-
In Übersetzungen vom Deutschen ins Englische liegt Normalisierung im Passivbereich vor, wenn in E-TL signifikant mehr Passive auftreten als in vergleichbaren englischen Texten (E-ORI)
Fallbeispiel: Passiv (Teich 2003)
-
Schwaches shining-through in G-TL

-
Keine Normalisierungs-Effekte in G-TL

Fallstudie: Passivalternativen (Teich 2003)
-
kein shining-through in E-TL

-
Normalisierung in E-TL

Zusammenfassung: Parallele Korpora


3. Vergleichbare Korpora
Bedarf an vergleichbaren Korpora
-
monolinguale und parallele Korpora allein eignen sich nicht für feiner granulare linguistische Forschung
-
da es ihnen entweder an Vergleichbarkeit oder an linguistischer Qualität mangelt
-
-
mögliche Abhilfe:
-
Kombination aus parallelen und einsprachigen Korpora verwenden
-
Nachteile:
-
(quantitative) Befunde nicht unmittelbar einschätzbar
-
datengeleitete Modelle u. U. irreführend
-
-
-
Desiderat: vergleichbare Korpora hoher Qualität
Vergleichbare Korpora
Definition (Kupietz et al. i.E.)
-
vergleichbare Korpora bestehen aus zwei oder mehreren einsprachigen Korpora,
-
die ähnliche Zusammensetzungen bzgl. potenziell relevanter Eigenschaften (Textsorte, Themenbereich, Zeit, Genre, ...) aufweisen
-
und (idealerweise) nur originalsprachliche Texte enthalten
-
-
frühes prominentes Beispiel:
-
International Corpus of English (ICE) (Greenbaum 1991)
-
enthält zwölf Korpora verschiedener nationaler oder regionaler Varietäten des Englischen mit einer kontrollierten, ähnlichen Zusammensetzungen
-
Gibt es vergleichbare Korpora?
… die auch Deutsch beinhalten
-
in Zukunft:
-
International Comparable Corpus (ICC) (Kirk/Čermáková 2017)
-
2017 gestartet Initiative
-
Ziel: Aufbau vieler kleiner Korpora mit kontrollierter Zusammensetzung
-
nach dem Vorbild des ICE
-
-
derzeit: nur web-basierte Korpora
-
Aranea - Familie vergleichbarer Gigaword-Webkorpora (Benko 2014)
-
Aranea im Einsatz
mit der NoSketch-Engine
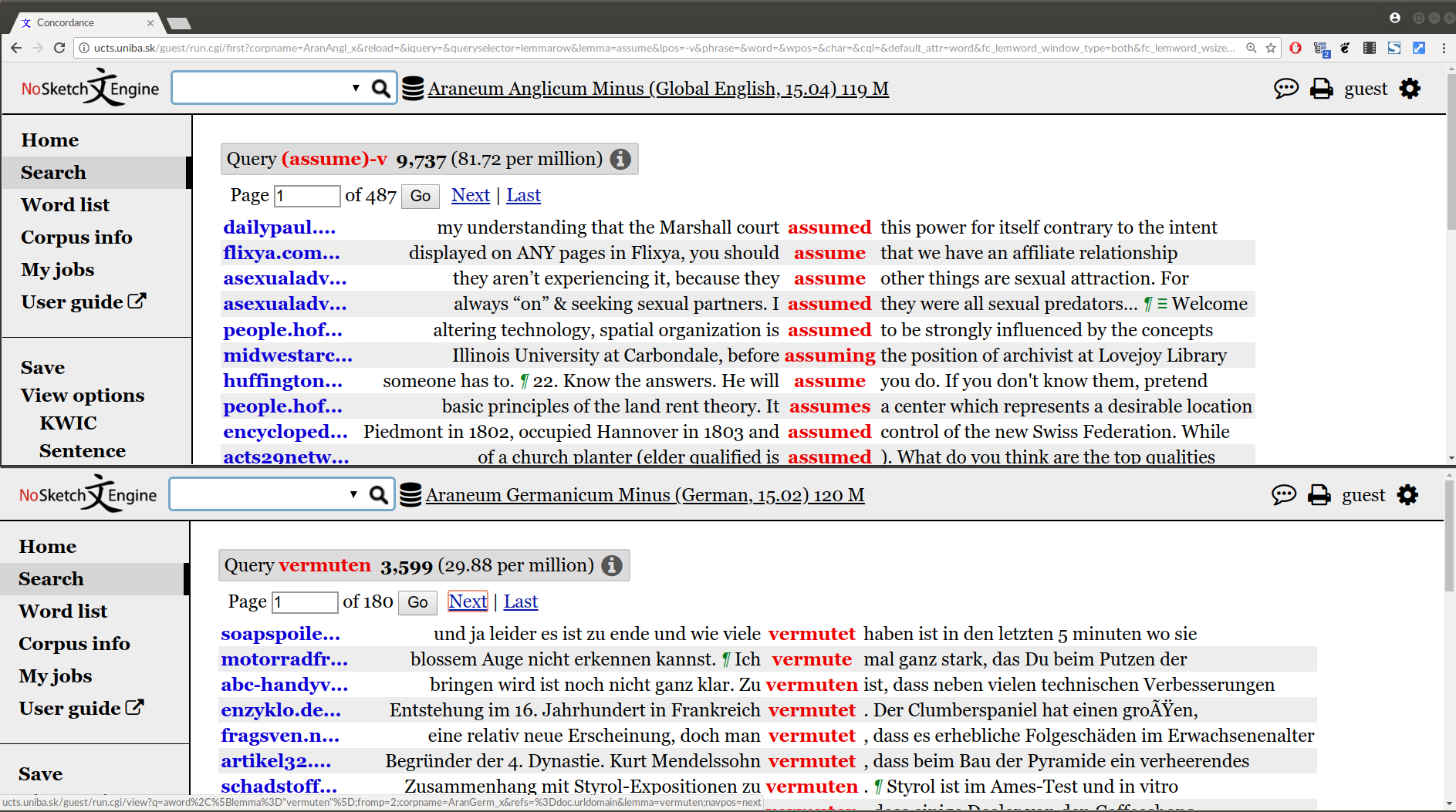
Aranea
Familie vergleichbarer Gigaword-Webkorpora (Benko 2014)
-
enthält mehr als 20 Sprachen
-
große Korpora kontrollierter Größe:
120M und 1.2G Wörter -
Nachteil:
-
die Vergleichbarkeit der Zusammensetzung ist nicht kontrolliert

-
und kann nicht leicht kontrolliert werden, da Texten aus dem Web notorisch die erforderlichen Metadaten fehlen
-
-
die Verfügbarkeit vergleichbarer Korpora, die auch Deutsch enthalten, ist nicht ideal.
Situation bei einsprachigen Korpora
-
viele National- und Referenzkorpora
-
BNC, CNC, CoRoLa, DeReKo , DWDS, HNC, NKJP, RNC, ...
-
-
nicht alle in aktiver Entwicklung
-
aber normalerweise mit einer gewissen institutionellen Unterstützung
4. EuReCo
EuReCo - European Reference Corpus
-
2013 gegründete offene Initiative
-
Polnische, Rumänische und Ungarische Akademie, IDS
-
-
Idee:
-
Kräfte bündeln und
-
bestehenden National- und Referenzkorpora gemeinsam nachnutzen
-
und sie durch neue Methoden und Technologien u.a.
zu virtuellen vergleichbaren Korpora verbinden
-
Erwartete Vorteile des EuReCo-Ansatzes
-
ökonomischer, skalierbarer und nachhaltiger
als vergleichbare Korpora von Grund auf neu zu erstellen-
da nur bestehende Korpora nachgenutzt werden
-
da man idealerweise auch von laufenden und zukünftigen Erweiterungen und Verbesserungen dieser Korpora profitieren kann
-
-
hohe linguistische Qualität und ausreichende Größe bei Nationalkorpora zu erwarten
-
Herausforderungen / Fragen
-
Wie können die bestehenden Korpora vergleichbar gemacht werden?
-
-
Wie können die bestehenden Korpora rechtskonform gemeinsam genutzt werden?
Problem: Urheberrecht und Lizenzverträge
... binden bestehende Korpora typischerweise an ihre Institutionen

If the data cannot move ...

... Find ways to put the computation near the data
Jim Gray (2003)

Übertragen auf EuReCo
... eine Infrastruktur aufbauen, um die Daten von dort aus zu nutzen, wo sie sich
befinden.
Erforderlich: Korpusanalyse-Tool
-
das basierend auf bestehenden, etwa in CLARIN entwickelten, Infrastrukturen
-
einen einheitlichen Zugang zu physisch verteilten Korpora bieten kann
-
und dem Benutzer ermöglicht, vergleichbare Korpora zu definieren:
-
z.B.: baue ein möglichst großes deutsch-ungarisches Vergleichskorpus mit gleicher Verteilung von Textsorten, Themen und Erscheinungsjahren zwischen 2000 und 2009
-
-
und die Daten entsprechend zu analysieren
KorAP
Die aktuelle technische Basis für EuReCo
-
zukünftiges Nachfolgesystem von COSMAS II
-
entwickelt v.a. am IDS seit 2011 (Bański et al. 2013, Diewald/Margaretha 2016)
-
es fehlen noch einige wichtige Funktionalitäten
-
alle aggregierenden quantitativen Funktionen
-
die aber über KorAPs R-Client-Bibliothek nachgebildet werden können
-
KorAP-Schlüsselmerkmale für EuReCo
-
KorAP kann mit physisch verteilten Daten arbeiten
-
alle Korpusdaten können bleiben, wo sie sind
-
-
erlaubt die dynamische Definition virtuellen Korpora
-
dynamische Konstruktion virt. vergleichbarer Korpora
-
-
unterstützt beliebig viele Annotationsschichten
-
sprachspezifische und UD-Annotationen möglich
-
-
unterstützt mehrere Abfragesprachen
-
übliche Anfragesprache kann weiter verwendet werden
-
-
hat eine nachhaltige Finanzierung
Wie erreicht man "Vergleichbarkeit"?
Grundlegender Ansatz: (Cosma et al. 2016)
-
man zieht Sub-Korpora aus den einsprachigen Korpora
-
so dass diese bzgl. Metadaten-Eigenschaften, wie:
-
Themenbereich
-
Texttyp
-
Veröffentlichungsdatum
-
…
-
-
möglichst ähnliche Tokenverteilungen aufweisen
Zu erwartende Herausforderungen
-
Stichprobenkonstruktion gegenüber der Arbeit mit monolingualen Korpora erschwert
-
beide Samples müssen repräsentativ für die jeweiligen Sprachdomänen sein
-
und sie bzw. die Sprachdomänen müssen vergleichbar sein
-
-
Metadatenkategorien und Taxonomien werden sicht oft unterscheiden
-
Textsorten, thematische Domänen, …
-
-
Korpora werden sich unterschiedlich zusammensetzen
-
je vergleichbarer man die Korpora macht desto kleiner werden sie
Iterativ und fragestellungsspezifisch vorgehen
zur schrittweisen Annäherung an ausreichende Vergleichbarkeit
-
mit einer guten Abbildung der Metadateneigenschaften beginnen
-
ein vorläufiges vergleichbares Korpuspaar definieren
-
vergleichende Fallstudien durchführen
-
falls die Befunde Artefakte von Vergleichbarkeitskriterien zu sein scheinen, Abbildung verfeinern und mit 2 neu beginnen
-

EuReCo-Entwicklungen der letzten Jahre
Zwei Pilot-Projekte
-
DRuKoLA (2016-2018)
-
vergleichende Studien zu Deutsch und Rumänisch
-
Universität Bukarest, Rumänische Akademie und IDS
-
erstes vergleichbares Korpus »drukola-1b« (900 Mio. Tokens) und
erste Studien publiziert (Cosma & Kupietz 2019)
-
-
DeutUng (2017-2020)
-
u.a. vergleichende Studien zu Deutsch und Ungarisch
-
Universität Szeged, Ungarische Akademie und IDS
-
Stand: HNC (Váradi 2002) tw. über KorAP abfragbar,
erst exemplarische Studien
-
-
beide gefördert von der Humboldt-Stiftung
-
als Institutspartnerschaften
-
DeutUng-Team

HNC teilweise über KorAP abfragbar
Erste exemplarische Vergleichsstudien
Korrelate im Ungarischen und Deutschen (Molnar 2015, Hartmann et al. 2017, Kupietz
et al i.E.)

DRuKoLa-Team

Herausforderungen bei der Konstruktion
von »drukola-1b«
-
automatische und dynamische Konstruktion des Vergleichskorpus noch nicht mit KorAP möglich
-
Downsampling-Funktion fehlt noch
-
-
Texttypen unterschiedlich klassifiziert und sehr unterschiedlich verteilt
-
Thementaxonomien jeweils 2 Ebenen aber unterschiedlich definiert
-
DeReKo basierend auf Open Directory Project (dmoz) (Weiß 2005, Klosa et al. 2012)
-
CoRoLa (Tufiş et al 2016) basierend auf Universal Decimal Classification (UDC) und Wikipedia top-level Domains (Gîfu et al. 2019)
-
Konstruktion von »DRuKoLA-1b«
-
Übersetzung der Thementaxonomie von CoRoLA auf die von DeReKo
-
z.B. Religion ➞ Staat/Gesellschaft:Kirche, Art and Culture ➞ Kultur, Medicine ➞ Gesundheit-Ernährung:Gesundheit
-
-
für 89% der CoRoLa-Texte konnten Abbildungen gefunden werden
-
einige Kategorien unvollständig, andere ungenau abgebildet
-
-
DeReKo groß genug, um CoRoLa's Themenverteilung vollständig zu imitieren
-
statt jeweils as CoRoLa und DeReKo eine Stichprobe zu ziehen, wurde nur aus DeReKo eine Stichprobe gezogen
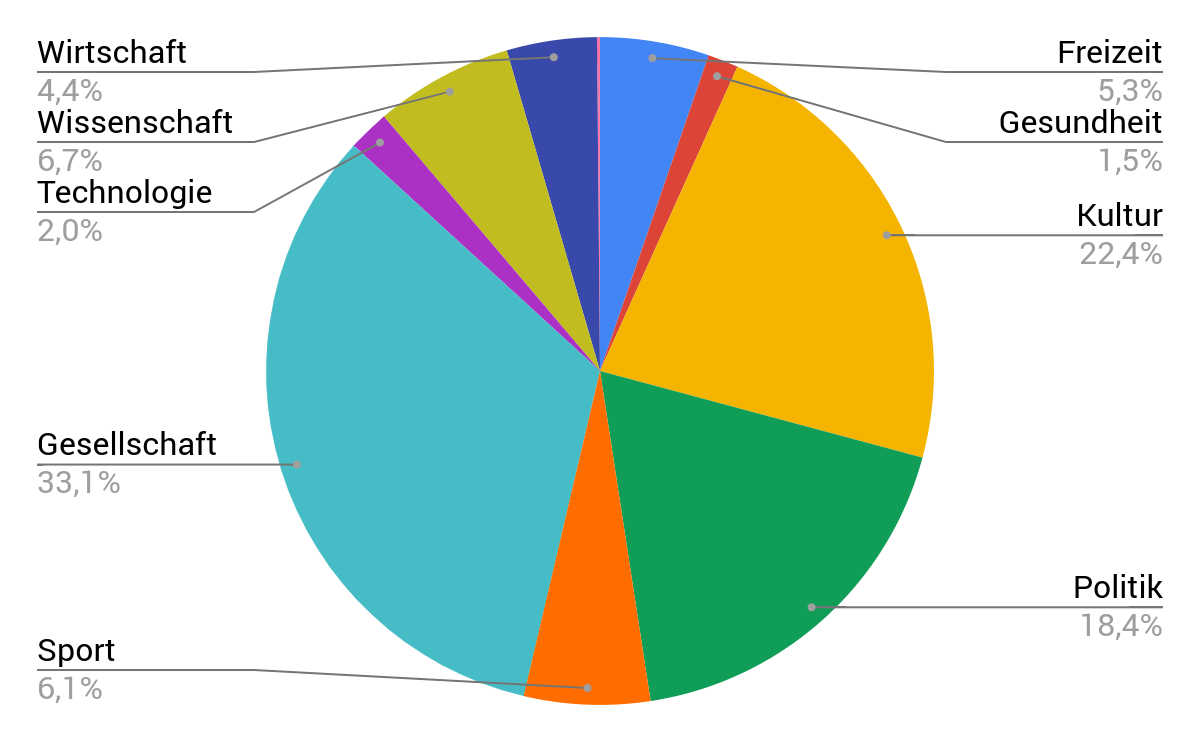
Thematische Zusammensetzung des Korpus
(nach DeReKo-Taxonomie)
Zusammensetzung nach Veröffentlichungsjahr
DeReKo/Deutsch-Anteil: nicht kontrolliertes Ergebnis der Stichprobenziehung
Verwendung unter KorAP
Weitere Evaluation bzgl. Vergleichbarkeit?
-
interessante Ansätze (Kutuzov et al. 2016, Saad et al 2013):
-
Berechnung der Ähnlichkeit anhand von
-
transformierten Word-Embedding-Modellen und
-
Semantic-Fingerprint-Clustern
-
-
unsere Experimente nicht sehr vielversprechend
-
außerdem:
-
gibt es m.E. ebenso so wenig allgemein »vergleichbare Korpa«
-
wie »repräsentative Korpora« oder »ausgewogene Korpora«
-
-
Vergleichbarkeit hängt sehr von der Fragestellung ab und ist allgemein kaum abschließend bewertbar
5. Schlussfolgerungen und Ausblick
Nächste EuReCo-Schritte
-
vollständige HNC-Integration
-
vereinfachte Einspeisung neuer Korpora in KorAP
-
verbesserte Integration von CoRoLa (Metadaten …)
-
Downsampling-Funktion für den KorAP-VC-Assitenten
-
Untersuchung unterschiedlicher definierter Vergleichskorpora
-
Auswirkung auf quantitative Verteilungen bei Fallstudien
-
-
hoffentlich die Integration weiterer großer Korpora
Zusammenfassung und Schlussfolgerungen
-
wir brauchen Korpora für den Sprachvergleich
-
je nach Fragestellung sind parallele, einsprachige, vergleichbare Korpora oder eine Kombination aus diesen geeignet
-
großes, übergreifendes Ziel:
-
-
EuReCo bietet einen realistischen Lösungsansatz
-
durch die virtuelle Vereinigung bestehender großer Korpora
-
nutzer-definierte, dynamische Konstruktion vergleichbarer Korpora
-
Vergleichbarkeit?
-
ob Korpora ausreichend vergleichbar sind, kann nicht allgemein entschieden werden, sondern ist u.a. von der Fragestellung abhängig
-
dynamisch definierbare vergleichbare Korpora, sind dazu der beste Lösungsansatz
-
im schlimmsten Fall kann mit EuReCo immerhin ein einheitlicher Zugang zu den einsprachigen Korpora erreicht werden
Vielen Dank für Ihre Aufmerksamkeit!
Referenzen
Augustin, Hagen (2017):
Verschmelzung von Präpositionen und Artikel. Eine kontrastive Analyse zum Deutschen und Italienischen. Reihe: Konvergenz und Divergenz 6.
Bański, Piotr/Bingel, Joachim/Diewald, Nils/Frick, Elena/Hanl, Michael/Kupietz, Marc/Pęzik, Piotr/Schnober, Carsten/Witt, Andreas (2013):
KorAP: the new corpus analysis platform at IDS Mannheim. In: Vetulani, Zygmunt/Uszkoreit, Hans (eds.): Human Language Technologies as a Challenge for Computer Science and Linguistics. Proceedings of the 6th Language and Technology Conference. S. 586-587 - Poznań: Fundacja Uniwersytetu im. A., 2013.
Benko, Vladimír (2014):
Aranea: Yet Another Family of (Comparable) Web Corpora. In Petr Sojka, Aleš Horák, Ivan Kopeček and Karel Pala (Eds.): Text, Speech and Dialogue. 17th International Conference, TSD 2014, Brno, Czech Republic, September 8-12, 2014. Proceedings. LNCS 8655. Springer International Publishing Switzerland, 2014. pp. 257-264. ISBN: 978-3-319-10815-5 (Print), 978-3-319-10816-2 (Online). BibTeX PDF
Borin, Lars/Forsberg, Markus/Roxendal, Johan (2012):
Korp – the corpus infrastructure of Språkbanken. In Proceedings of LREC 2012. Istanbul: Elra, 474–478
Brandt, Patrick unter Mitwirkung von Felix Bildhauer (2019):
Alternation von zu- und dass- Komplementen: Kontrolle, Korpus, und Grammatik. In: Fuß, Eric/Konopka, Marek/Wöllstein, Angelika. Grammatik im Korpus. Korpuslinguistisch-statistische Analysen morphosyntaktischer Variationsphänomene. Tübingen: Narr.
Brandt, Patrick/Trawiński, Beata/Wöllstein, Angelika (2017):
(Anti-)Control in German: Evidence from Comparative, Corpus- and Psycholinguistic Studies. In: Linguistische Berichte (Sonderheft). Hamburg: Buske.
Čermák, František/Rosen, Alexandr (2012):
The case of InterCorp, a multilingual parallel corpus. In International Journal of Corpus Linguistics, 17(3), 411–427.
Chesterman, Andrew (1998):
Contrastive Functional Analysis. Amsterdam/Philadelphia: John Benjamins Publishing Company.
Cosma, Ruxandra/Cristea, Dan/Kupietz, Marc/Tufiş, Dan/Witt, Andreas (2016):
DRuKoLA – Towards Contrastive German-Romanian Research based on Comparable Corpora. In: Bański, Piotr/Barbaresi, Adrien/Biber, Hanno/Breiteneder, Evelyn/Clematide, Simon/Kupietz, Marc/Lüngen, Harald/Witt, Andreas: 4th Workshop on Challenges in the Management of Large Corpora. Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC 2016), Portorož, Slowenien. Paris: European Language Resources Association (ELRA), 2016. pp 28-32.
Cysouw M./Wälchli B. (2007):
Parallel texts: using translational equivalents in linguistic typology. STUF - Sprachtypologie und Universalienforschung 60(2), 95–99.
Diewald, Nils/Margaretha, Eliza (2016):
Krill: KorAP search and analysis engine. In: Kupietz, Marc/Geyken, Alexander (Hrsg.): Corpus Linguistic Software Tools. Journal for language technology and computational linguistics (JLCL) 31 (1). (= Journal for Language Technology and Computational Linguistics 31.1). Berlin: GSCL, 2016. S. 73-90.
Gîfu, D., Moruz, A., Bolea, C., Bibiri, A. & Mitrofan, M. (2019):
The Methodology of Building CoRoLa. Revue roumaine de linguistique (3), 241-253.
Granger, S./Lerot, J./Petch-Tyson, S. (Eds.) (2003):
Corpus-based Approaches to Contrastive Linguistics and Translation Studies. Amsterdam / Atlanta: Rodopi.
Granger, S. (2010):
Comparable and translation corpora in cross-linguistic research. Design, analysis and applications. Journal of Shanghai Jiaotong University.
Gray, Jim (2003):
Distributed Computing Economics. Technical Report MSR-TR-2003-24, Microsoft Research.
Greenbaum, Sidney (1991):
ICE: The international corpus of English. English Today, 7(4), 3-7.
Gunkel, Lutz / Murelli, Adriano / Schlotthauer, Susan / Wiese, Bernd / Zifonun, Gisela (2017):
Grammatik des Deutschen im europäischen Vergleich – Das Nominal. Unter Mitarb. v. Günther, Christine / Hoberg, Ursula. Reihe: Schriften des Instituts für Deutsche Sprache 14.
Hartmann/Mucha/Trawiński/Wöllstein (in Vorbereitung):
Antikontrolle und Satzwertigkeit. In Beata Trawinski und Angelika Wöllstein (ed.): Perspektiven im Sprachvergleich. Pilotstudien zu einer Grammatik des Deutschen im Europäischen Vergleich. Reihe: Konvergenz und Divergenz. De Gruyter.
Hartmann, J. M., Schlotthauer, S., Trawiński, B. & Wöllstein, A. (2017):
Sprachvergleich: Einblicke in die aktuelle kontrastive Forschung am IDS: Nominal- und Verbgrammatik. Presentation at the Kick-off of the project DeutUng, 19.10.2017, University of Szeged (Hungary).
James, Carl (1980):
Contrastive Analysis. London: Longman.
Johansson, S. (1999):
Corpora and contrastive studies. In P. Pietilä & O-P. Salo (Hrgs.) Multiple Languages – Multiple Perspectives. AFinLA Yearbook 1999 / No. 57, 116-125.
Johansson, S. (2007):
Seeing through multilingual corpora. On the use of corpora in contrastive studies. Amsterdam: Benjamins.
Kirk, John, Anna Cermakova, Signe Oksefjell Ebeling, Jarle Ebeling, Michal Kren, Karin Aijmer, Vladimir Benko, Radovan Garabik, Rafal Gorski, Jarmo Jantunen, Marc Kupietz, Maria Simkova, Thomas Schmidt and Oliver Wicher (to appear in 2018):
Introducing the International Comparable Corpus. In Granger, S. & Lefer, M.-A. (eds.): Book of Abstracts of the Using Corpora in Contrastive and Translation Studies Conference (5th edition), Louvain-la-Neuve, 12-14 September 2018. CECL Papers 1, UCLouvain, Louvain-la-Neuve.
Kirk, John/Čermáková, Anna (2017):
From ICE to ICC: The new International Comparable Corpus. In Bański et al. (eds.): Proceedings of the Workshop on Challenges in the Management of Large Corpora and Big Data and Natural Language Processing (CMLC-5+BigNLP) 2017 including the papers from the Web-as-Corpus (WAC-XI) guest section
Koehn, Philipp (2005):
Europarl: A Parallel Corpus for Statistical Machine Translation. MT Summit 2005.
Kupietz, Marc/Belica, Cyril/Keibel, Holger/Witt, Andreas (2010):
The German Reference Corpus DeReKo: A primordial sample for linguistic research. In: Calzolari, Nicoletta et al. (eds): Proceedings of the seventh conference on International Language Resources and Evaluation (LREC 2010). S. 1848-1854 - ELRA.
Kupietz, Marc/Witt, Andreas/Bański, Piotr/Tufiş, Dan/Cristea, Dan/Váradi, Tamás (2017):
EuReCo – Joining Forces for a European Reference Corpus as a sustainable base for cross-linguistic research. In: Bański, Piotr et al. (eds.): Proceedings of the Workshop on Challenges in the Management of Large Corpora and Big Data and Natural Language Processing (CMLC-5+BigNLP) 2017 including the papers from the Web-as-Corpus (WAC-XI) guest section. Birmingham, 24 July 2017. Mannheim: Institut für Deutsche Sprache, 2017. pp. 15-19.
Kupietz, Marc/Cosma, Ruxandra/Cristea, Dan/Diewald, Nils/Trawiński, Beata/Tufiş, Dan/Váradi, Tamás/Wöllstein, Angelika (i. E.):
Recent Developments in the European Reference Corpus EuReCo. In Granger, S. & Lefer, M.-A. (eds) (forthcoming). Proceedings of the Using Corpora in Contrastive and Translation Studies Conference (5th edition). Louvain-la-Neuve: Presses universitaires de Louvain.
Kutuzov, A., Kopotev, M., Sviridenko, T. & Ivanova, L. (2016):
Clustering Comparable Corpora of Russian and Ukrainian Academic Texts: Word Embeddings and Semantic Fingerprints. In: Rapp, R., Zweigenbaum, P., Sharoff, S. (eds.): Proceedings of the Ninth Workshop on Building and Using Comparable Corpora. Portorož, Slovenia: ELDA, pp. 3-10.
Molnár, Valéria (2015):
The Predicationality Hypothesis. The Case of Hungarian and German. In É. Kiss, K., Surányi, B. & É. Dékány (eds). Approaches to Hungarian 14. Papers from the 2013 Piliscsaba Conference. Amsterdam: Benjamins, 209–244.
Rapp, Irene/Laptieva, Ekaterina/Koplenig, Alexander/Engelberg, Stefan (2017):
Lexikalisch-semantische Passung und argumentstrukturelle Trägheit – eine korpusbasierte Analyse zur Alternation zwischen dass-Sätzen und zu-Infinitiven in Objektfunktion. Deutsche Sprache 45(3). 193-221.
Saad, M., Langlois, D., & Smaïli, K. (2013):
Extracting Comparable Articles from Wikipedia and Measuring their Comparabilities,
Procedia - Social and Behavioral Sciences, Volume 95, 40-47.
Steinberger, Ralf/Pouliquen, Brun/Widiger Anna/Ignat, Camelia/Erjavec, Tomaz/Tufis, Dan/Varga Da’niel (2006):
The JRC-Acquis: A multilingual aligned parallel corpus with 20+ languages. In Proceedings of the 5th International Conference on Language Resources and Evaluation (LREC 2006) .
Taborek, Janusz (2018):
Korpusbasiertes kontrastives Beschreibungsmodell für Funktionsverbgefüge.
In: Schmale, Günter (ed.): Lexematische und polylexematische Einheiten des Deutschen (Reihe Eurogermanistik), Tübingen: Stauffenburg, 135-154.
Teich, Elke (2003):
Cross-Linguistic Variation in System and Text: A Methodology for the Investigation of Translations and Comparable Texts. Berlin: Mouton de Gruyter.
Tufiş, D., Barbu Mititelu, V., Irimia, E., Dumitrescu, Ș. D. and Boroş, T. (2016):
The IPR-cleared Corpus of Contemporary Written and Spoken Romanian Language. In: Calzolari, N. et al. (eds.): Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC'16), Portoroz / Paris: ELRA.
van Noord, Gertjan/Bouma, Gosse/van Eynde, Frank/de Kok, Daniel/van der Linde, Jelmer/ Schuurman, Ineke/Sang, Erik Tjong Kim/Vandeghinste, Vincent. (2013):
Large Scale Syntactic Annotation of Written Dutch: Lassy. In Peter Spyns and Jan Odijk (eds.), Essential Speech and Language Technology for Dutch: the STEVIN Programme, 147–164, Springer.
Váradi, T. (2002):
The Hungarian National Corpus. In Rodríguez, M. & Araujo, C. (eds) Proceedings of LREC 2002, Las Palmas / Paris: ELRA, 385–389.
Anhang
Mehrsprachige Korpora
Es ist oft gesagt worden, dass wir durch Korpora Muster in der Sprache beobachten können, die wir vorher nicht kannten (...) Meine Behauptung ist, dass dies insbesondere für mehrsprachige Korpora gilt. Wir können sehen, wie sich Sprachen unterscheiden, was sie gemeinsam haben und - vielleicht irgendwann - was Sprache im Allgemeinen charakterisiert.
Johansson (2007)
Verteilung über Konzepte
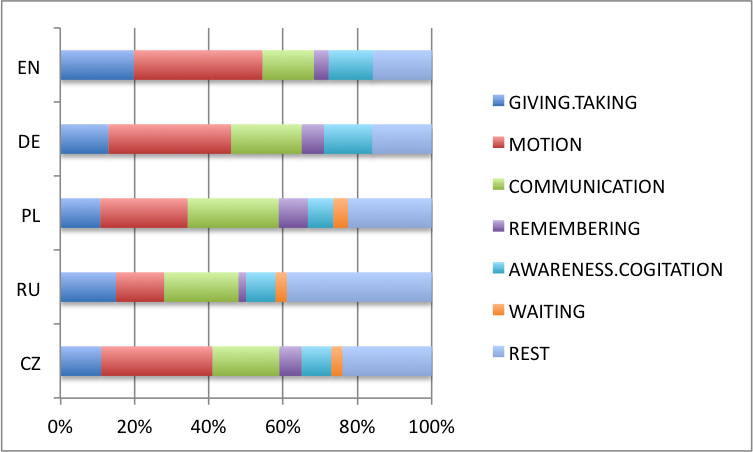
Verbkategorien 1: Schwedisch
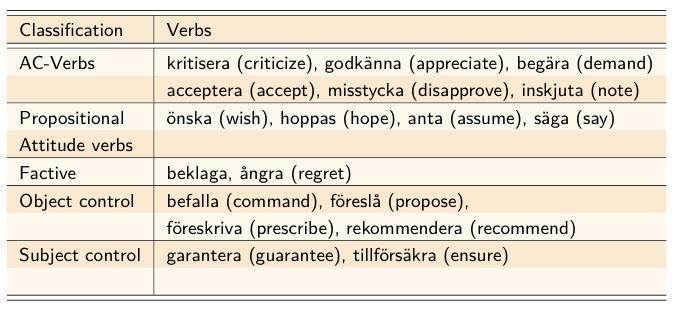
Verbkategorien 2: Schwedisch
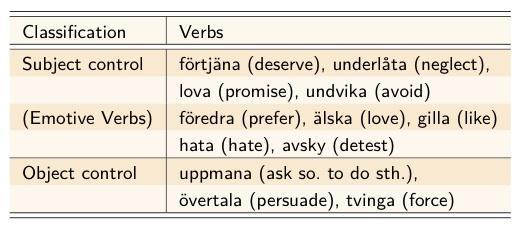
Verbkategorien 3: Schwedisch

Mögliche Anfragen
[drukola/m=pos:particle & drukola/m=type:negative] {,5} decît
Thematische Zusammensetzung des Korpus
nach CoRoLa-Taxonomie
Flache quantitative Merkmale
Flache quantitative Merkmale: Wortarten
Grafiken alle mit KorAP-R-Client-Package generiert
library(RKorAPClient)
library(tidyverse)
library(highcharter)
library(kableExtra)
D <- new("KorAPConnection", verbose=T)
B <- D
DRuKoLAVC <- "referTo+drukola.20180909.1b_words"
baseVC = "corpusSigle=/U[0-9][0-9]/ | corpusSigle=/W.D17/"
R <- new("KorAPConnection", KorAPUrl = "http://89.38.230.10:5555/", verbose=T)
Dsize <- corpusStats(D, vc=DRuKoLAVC)@tokens
Rsize <- corpusStats(R)@tokens
Bsize <- corpusStats(D, vc=baseVC)@tokens
queryResultToHtml <- function(r) {
link <- slice(r, which.min(f))$webUIRequestUrl # use the query with less results
text_spec(round(r[1,]$f,2), color="blue", link=link, tooltip = r[1,]$query %>% str_replace_all('"', '"')) %>% str_replace(">", 'target="korap">')
}
add_comp <- function(.data, cat, n1, n2, b1) {
Abhängigkeit von einer Software
-
Abhängigkeit von einer einzigen Software?
-
KorAP ist ein Open-Source-Projekt
-
einfacher ein zusätzliches Korpusabfragetool einzusetzen, als eine äquivalente API für viele Korpuswerkzeuge zu entwickeln und zu pflegen
-